
Trabajar con infraestructura de almacenamiento empresarial como Dell PowerScale (Isilon) suele dar tranquilidad por su alta disponibilidad. Sin embargo, cuando el mecanismo de autoprotección de OneFS entra en acción, puede desencadenar un efecto dominó que detiene la producción por completo.
Recientemente nos enfrentamos a un incidente crítico en OneFS 9.7.1.3 donde un fallo de batería (BBU) escaló hasta la pérdida total de acceso a los discos compartidos (SMB/NFS) y la caída de la WebUI.
En este post documentaré los síntomas, la causa raíz, el procedimiento de contingencia (workaround) y, lo más importante, por qué forzar la salida del modo Read-Only conlleva un riesgo masivo de pérdida de datos si no se calcula correctamente.
1. El Síntoma: Efecto Dominó en OneFS
Todo comenzó con reportes de pérdida de escritura a las carpetas compartidas. Al intentar investigar desde la consola de administración web (WebUI), el sistema arrojó comportamientos erráticos:
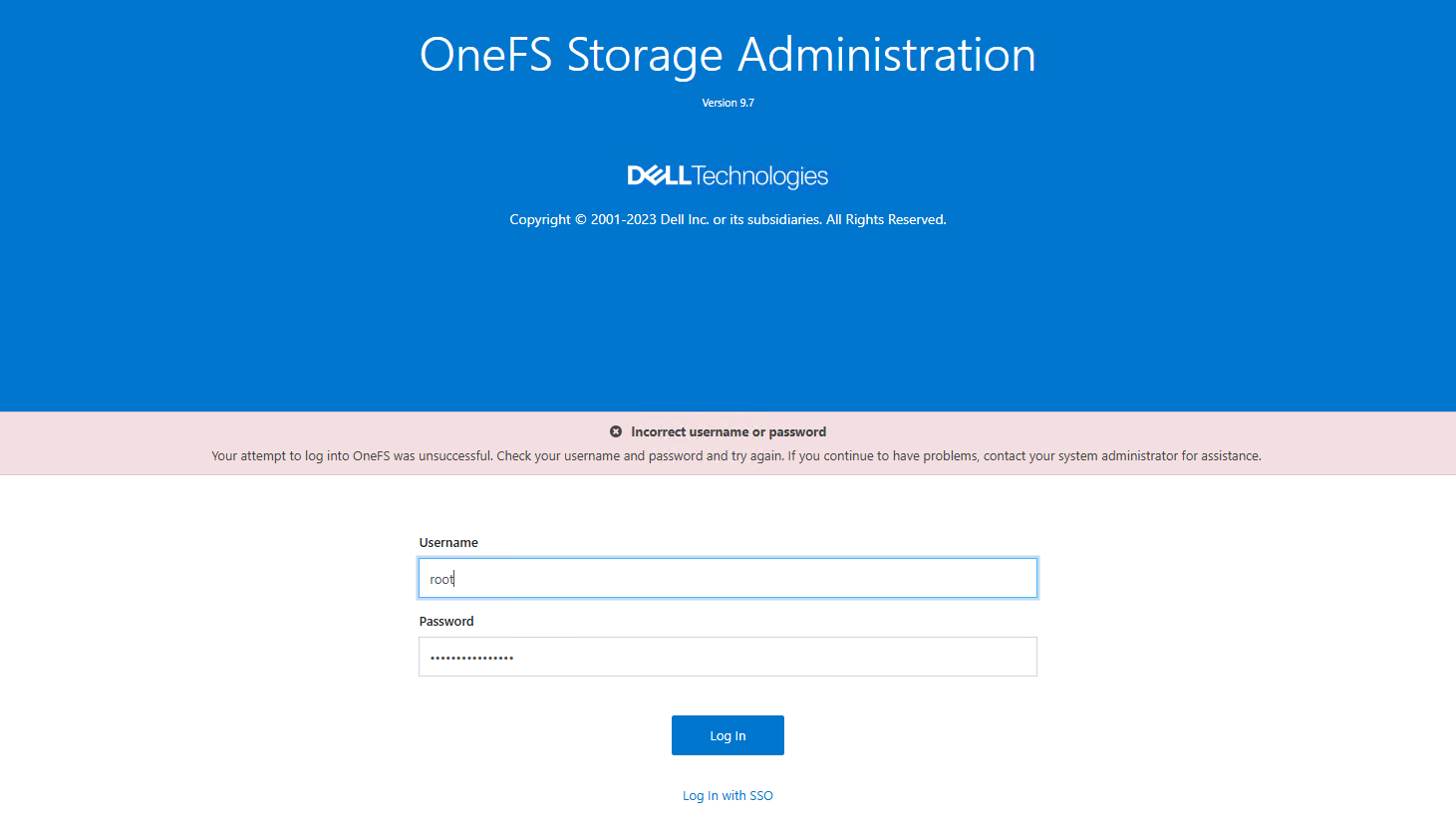
- Al intentar login local con
rootoadmin, el portal devolvía un engañosoIncorrect password.
- Al intentar entrar vía SSO (SAML), el servidor colapsaba devolviendo un
HTTP 500 (Internal Server Error).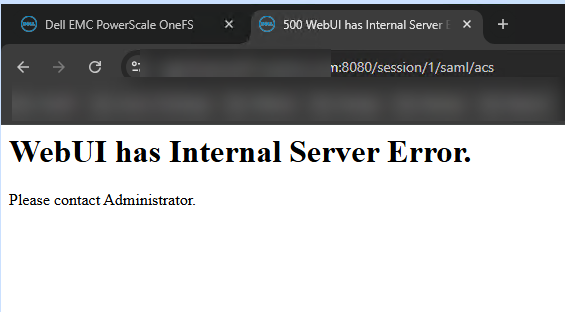
Afortunadamente, el acceso por SSH como root seguía vivo. Al revisar el estado del clúster, el panorama fue claro:
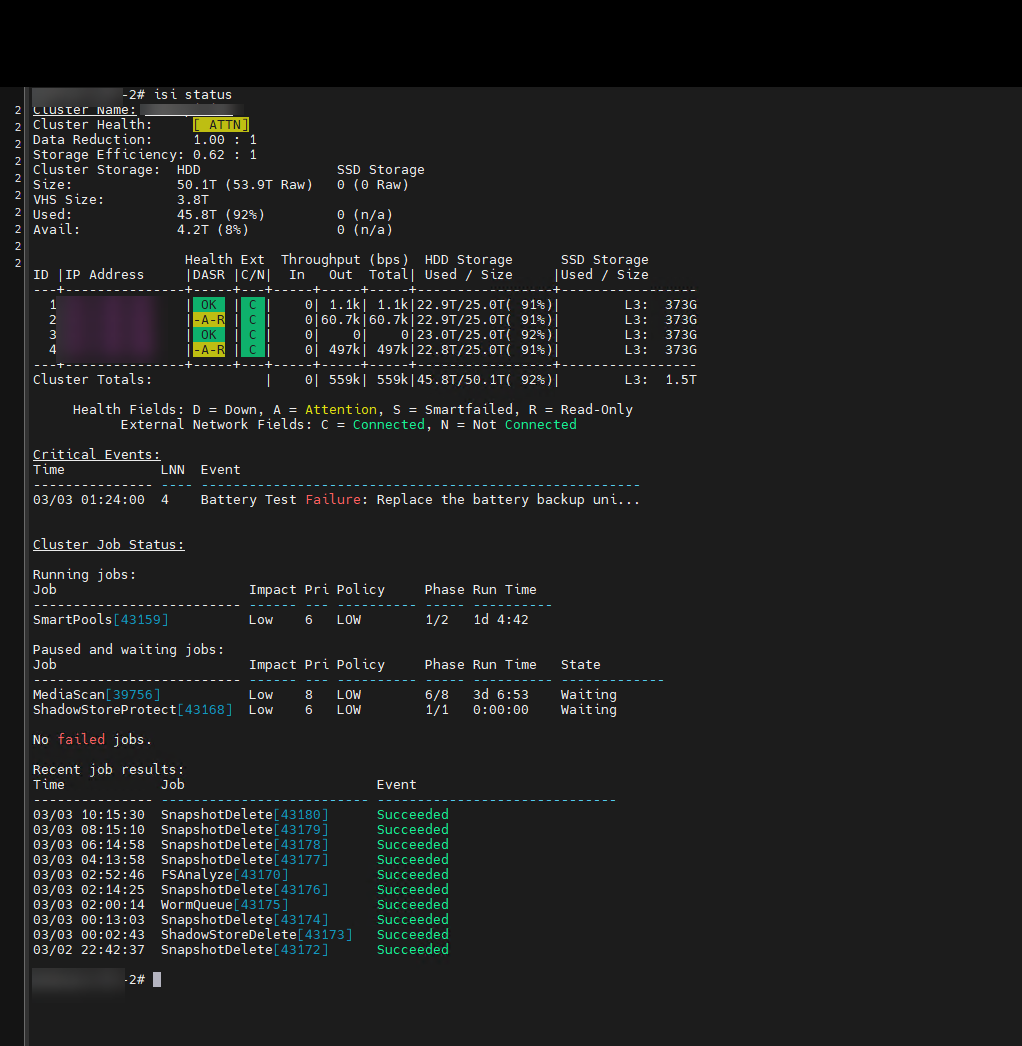
Dos de nuestros cuatro nodos habían entrado en estado -A-R (Attention / Read-Only).
2. La Causa Raíz: El Journal, la NVRAM y el Bloqueo de /ifs
El evento crítico indicaba: Battery Test Failure: Replace the battery backup unit en el Nodo 4.
En la arquitectura Isilon, las escrituras no van directo a los discos físicos. Primero pasan por una memoria ultrarrápida (NVRAM) que actúa como caché (journal). Si el nodo sufre un corte de energía, la batería de respaldo (BBU) da la energía suficiente para volcar el contenido de la NVRAM a un disco flash interno seguro.
Si la BBU falla, OneFS pone el nodo inmediatamente en modo de Solo Lectura (Read-Only) para evitar corrupción en caso de apagón.
El problema fue matemático: al perder la capacidad de escritura en el 50% de los nodos, el clúster ya no podía garantizar el nivel de protección de datos (Erasure Coding) para nuevas escrituras. Para proteger la integridad global, OneFS entró en autoconservación y bloqueó todo el sistema de archivos (/ifs) en modo Read-Only.
Al bloquearse /ifs:
- Los usuarios no pueden escribir en SMB/NFS.
- El servicio de autenticación (
lsass) colapsa al no poder escribir tokens de sesión (causando el error de contraseña). - La WebUI se cae al intentar procesar los tokens de SAML/SSO.
3. El Procedimiento de Recuperación (Paso a Paso)
Antes de comprometer los datos, ejecutamos los siguientes pasos de diagnóstico y contención junto con el soporte de Dell.
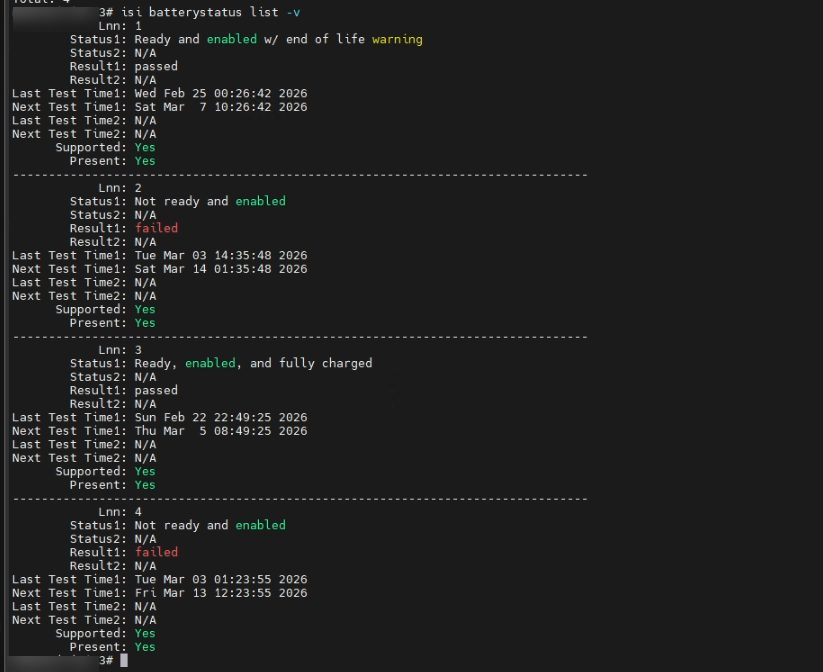
Paso 1: Diagnóstico
Confirmamos el fallo de baterías de todos los nodos.
# Check battery and NVRAM charge status across all nodes
isi batterystatus list -v
Paso 2: Restaurar el Quorum (La Intervención)
Se determinó que el Nodo 2 había entrado en Read-Only por protección cruzada, pero el fallo real de hardware estaba solo en el Nodo 4.
Para recuperar el quorum de escritura sin arriesgar todo el clúster, Dell procedió a remover el candado lógico exclusivamente en el Nodo 2. En versiones de OneFS 9.x, este es el comando correcto:
# Disable logical read-only state on Node 2 to restore write quorum
isi readonly modify --enabled=no --allowed=no --node-lnn 2
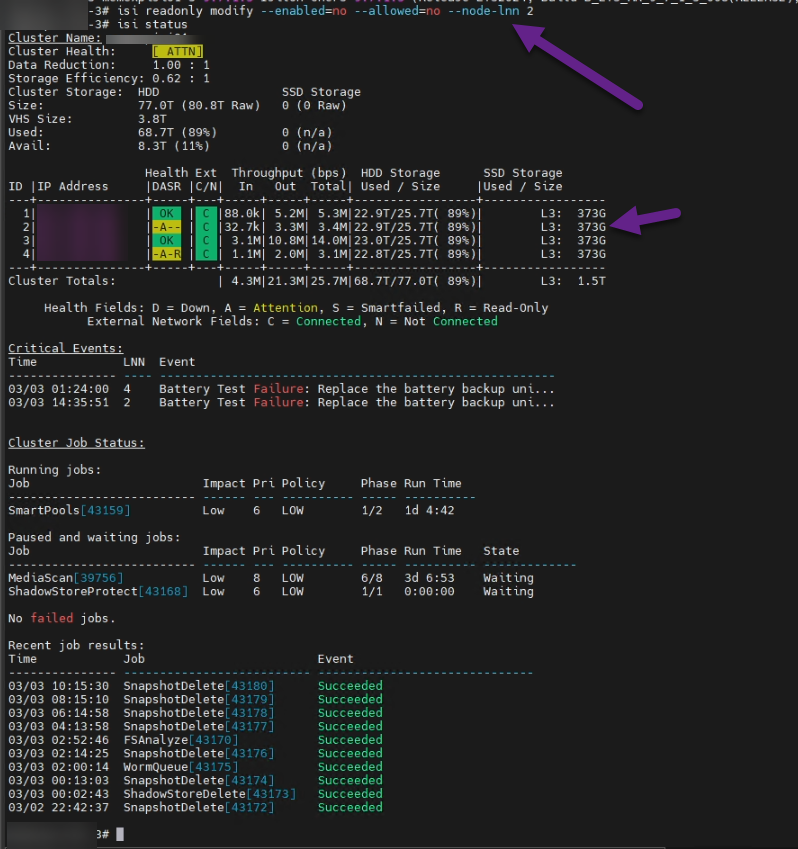
Como se observa, el Nodo 2 pasó de [-A-R] a [-A--]. Al recuperar la capacidad de escritura de ese nodo, se levantó el bloqueo global sobre /ifs, lsass revivió y la producción continuó.
⚠️ PELIGRO CRÍTICO: EL RIESGO DE FORZAR LA SALIDA DEL READ-ONLY ⚠️
Sacar un nodo del modo Read-Only cuando existe un fallo físico de batería no es una solución definitiva, es una apuesta calculada.
¿Qué pasa si lo haces mal? Al forzar un nodo a aceptar escrituras sin una BBU confiable, su NVRAM queda totalmente expuesta. Si ocurre un corte de energía en ese instante, todos los datos “en tránsito” (el journal) se evaporan para siempre.
¿Por qué Dell solo liberó un nodo? Isilon utiliza Forward Error Correction. Si hay un apagón y un solo nodo pierde su journal, el clúster puede reconstruir esos datos usando la paridad de los nodos sanos. Si hubiéramos forzado la salida de los dos nodos afectados (2 y 4) y ocurría un fallo eléctrico, perderíamos los journals de ambos simultáneamente. Esto superaría la tolerancia a fallos, resultando en corrupción irreversible del sistema de archivos.
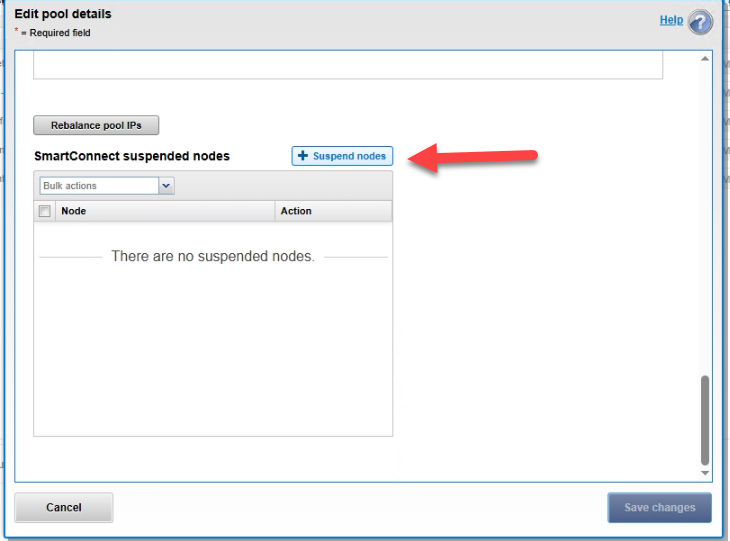
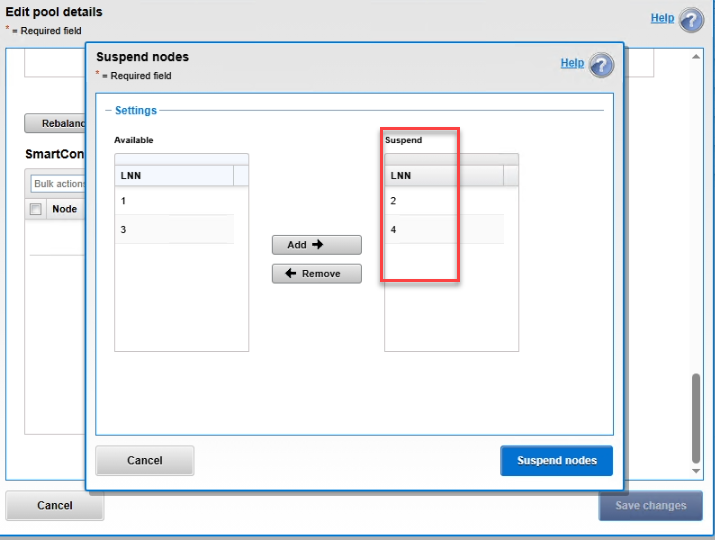
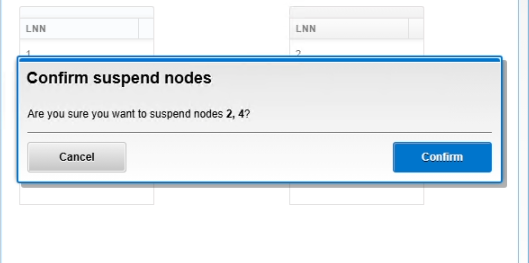
Paso 3: Aislar los nodos del tráfico de usuarios (SmartConnect)
Para evitar que el balanceador enviara usuarios a los nodos bloqueados, pausamos su participación en los pools de producción.
Al remover el nodo 2 de solo lectura volvemos a ganar acceso a la página de administración con la cuenta admin, ingresa y sigue los siguientes pasos.
1. Network Configuration
2. Edit Pool SMB
3. Edit the details
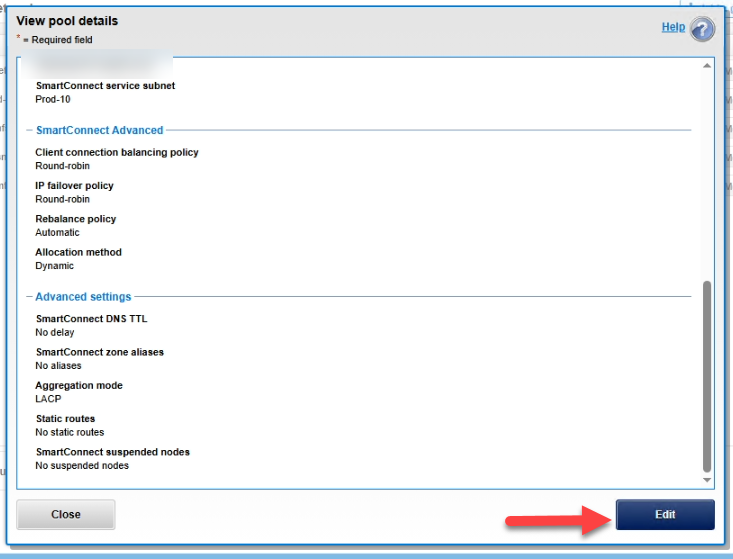
4. Suspend the affected nodes

Conclusión
Este workaround salvó la operación local sin obligarnos a levantar el entorno de Disaster Recovery en nuestra réplica, pero nos dejó operando con una red de seguridad muy fina en lo que se hace el reemplazo de las baterias.
Reglas de oro:
Nunca subestimes una alerta de hardware de OneFS; su prioridad siempre es proteger los datos, no mantener la red arriba.
Jamás fuerces la salida de un nodo en Read-Only sin entender la matemática de tolerancia a fallos de tu clúster.
Asegura tus UPS, vigila de cerca la capacidad (estar al 92% reduce dramáticamente el margen de maniobra) y ten tus políticas de SyncIQ listas para un failover si la intervención local es demasiado riesgosa.