
Introducción: La Evolución de un Pipeline
En las entradas anteriores de esta serie, detallé mi travesía desde un embotellamiento catastrófico de 25 minutos desplegando por SFTP, hasta un pipeline híper-optimizado basado en Rsync que completa la tarea en cuestión de segundos. Pero la optimización es solo la mitad de la batalla en la Arquitectura Empresarial. La otra mitad es la Resiliencia (Alta Disponibilidad).
Actualmente, mi pipeline depende en su totalidad de la infraestructura en la nube de Microsoft (GitHub). Aunque Actions provee 2,000 minutos gratuitos de CI/CD al mes, depender al 100% de recursos de cómputo externos viola un principio fundamental del Auto-Alojamiento (Self-Hosting): El Control. ¿Qué pasa si quemo todos mis minutos gratuitos durante semanas de desarrollo intenso? ¿Qué ocurre si las colas públicas de los runners de GitHub sufren una caída del servicio?
Tengo un clúster Proxmox en mi casa (“Homelab”) que se la pasa ocioso. ¿Por qué estoy delegando mi tiempo de procesamiento a la nube pública y arriesgándome a toparme con límites duros cuando soy dueño de mi propio hardware?
En este post exploraré la evolución final de mi arquitectura de despliegue: El Pipeline Híbrido (Hybrid Cloud). Implementaremos un “Self-Hosted Runner” de GitHub en una máquina virtual local, delegaremos el 99% de nuestro procesamiento al Homelab, y configuraremos inteligentemente la nube de GitHub original para actuar exclusivamente como un “Fallback” (Plan B) automatizado de recuperación ante desastres.
Paso 1: Desplegando el Self-Hosted LXC Runner
Un “Self-Hosted Runner” de GitHub es esencialmente un pequeño agente (un daemon) que instalas en tu propia infraestructura. Cuando haces un push de código, GitHub no enciende un contenedor en sus propios servidores. En su lugar, envía un webhook encriptado hacia tu agente: “Tengo un trabajo de integración para ti”. Tu servidor local hace la carga pesada (como compilar Hugo y correr Rsync) y reporta el estatus de vuelta a GitHub.
Cómo Instalarlo:
- En tu repositorio de GitHub, navega a Settings > Actions > Runners.
- Da clic en New self-hosted runner y selecciona Linux (x64).
- Levanté un contenedor ligero (LXC) con Ubuntu 22.04 en mi clúster Proxmox específicamente para esta tarea para mantener el consumo de recursos al mínimo.
Requisitos previos en el contenedor LXC
Por qué no podemos ejecutar el runner como root:
Los runners de GitHub Actions están diseñados explícitamente para bloquear la ejecución bajo la cuenta root por razones críticas de seguridad. Ejecutar como root viola el principio de Privilegio Mínimo: cualquier paso del flujo de trabajo o acción de terceros ejecutada por el runner tendría acceso sin restricciones a todo tu sistema host o contenedor LXC. Esto crea una superficie de ataque masiva donde una sola dependencia comprometida podría resultar en el control total del sistema. Al usar un usuario dedicado github, aseguramos que el runner opere dentro de un “sandbox” donde sus permisos están limitados estrictamente a lo necesario para compilar y desplegar tu código.
# Actualizar listas de paquetes e instalar herramientas esenciales
apt-get update && apt-get upgrade -y
apt-get install -y curl git tar libicu-dev
# Crear un usuario dedicado llamado 'github' con directorio personal y shell bash
useradd -m -s /bin/bash github
# Agregar el usuario al grupo sudoers (necesario para la instalación del servicio)
usermod -aG sudo github
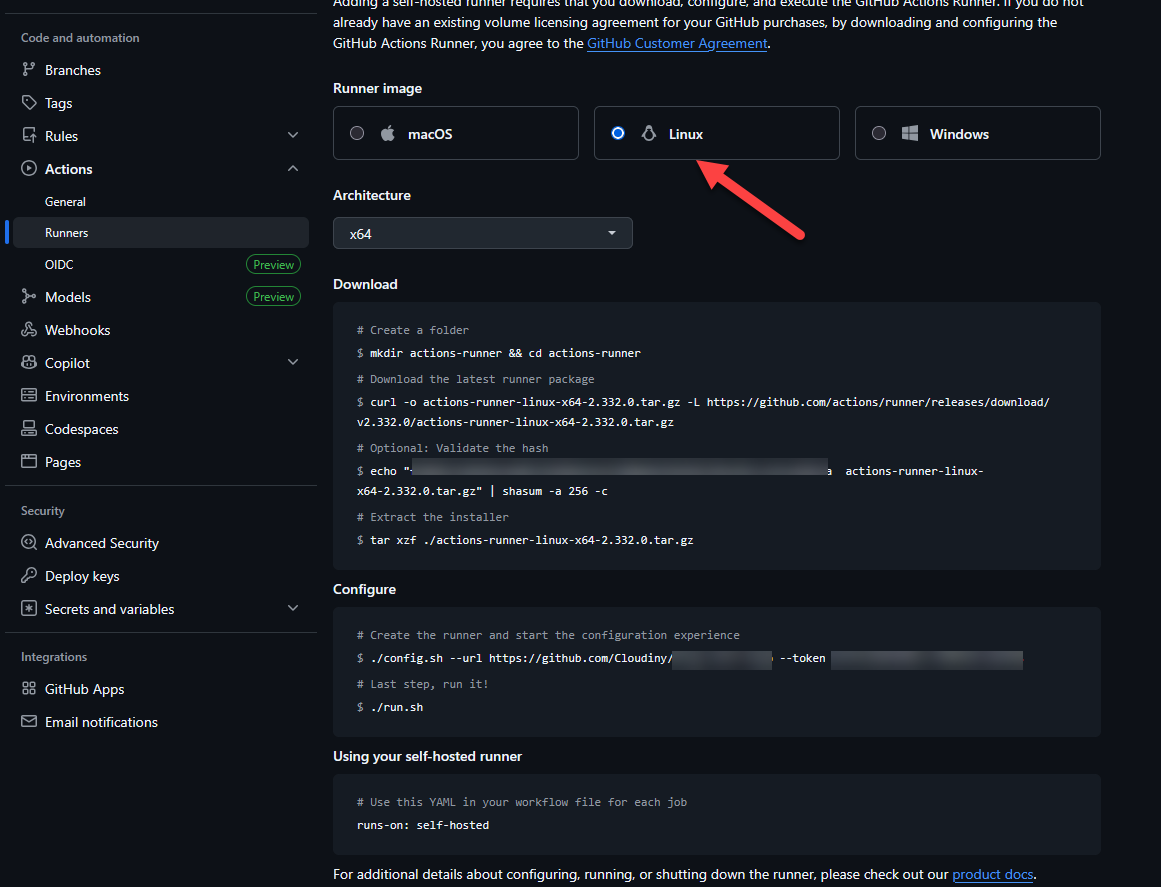
- Ejecuta los comandos bash provistos por GitHub para descargar y configurar el agente:
Descarga y Extracción
# Cambiar al usuario github
su - github
# Crear una carpeta y entrar en ella
mkdir actions-runner && cd actions-runner
# Descargar el paquete del runner más reciente
curl -o actions-runner-linux-x64-2.332.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.332.0/actions-runner-linux-x64-2.332.0.tar.gz
# Extraer el instalador
tar xzf ./actions-runner-linux-x64-2.332.0.tar.gz

Configuración
# Iniciar la experiencia de configuración
./config.sh --url https://github.com/TuUsuario/TuRepo --token TU_TOKEN_SECRETO
# Último paso: Ejecutarlo manualmente para la primera prueba
./run.sh
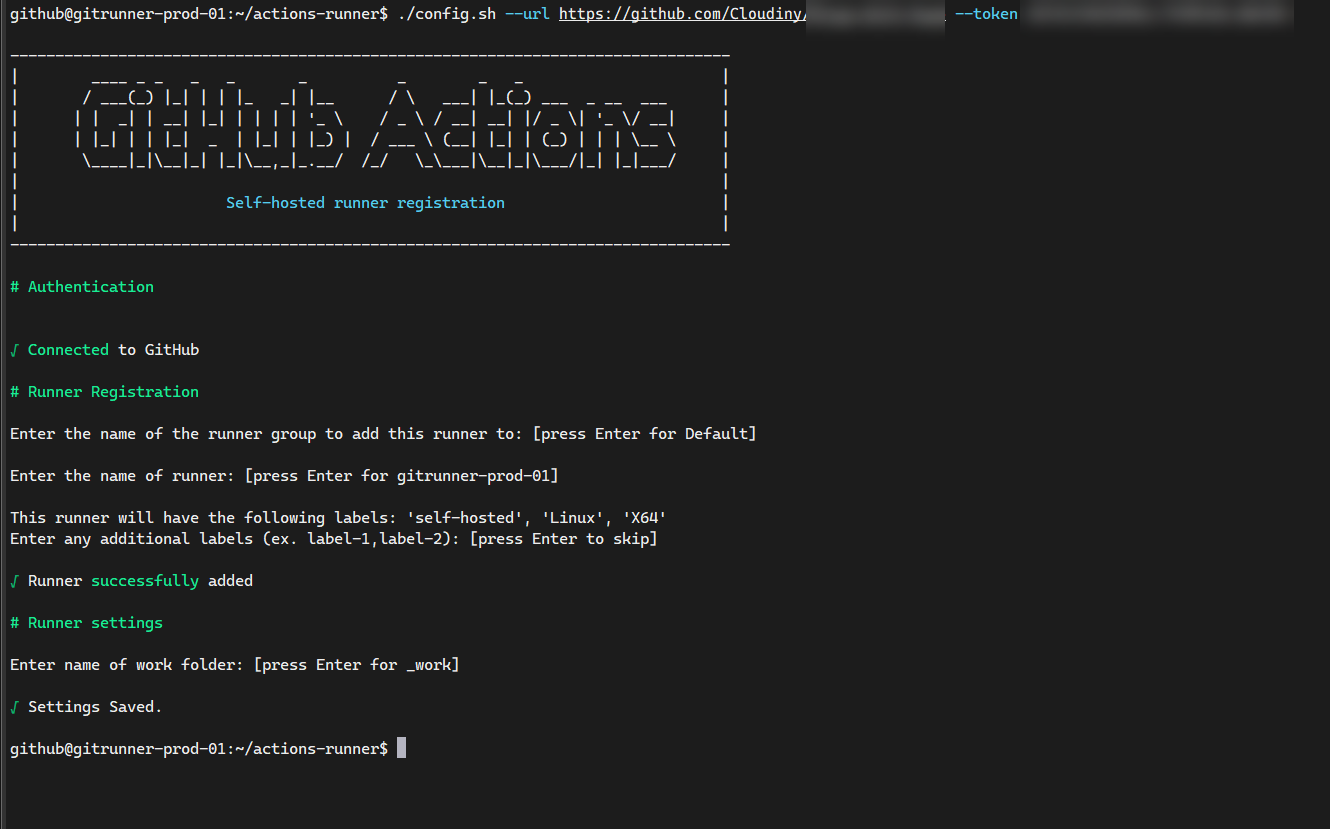
Regresa a GitHub y tu runner debería verse ahora como “Idle” (Ocioso)
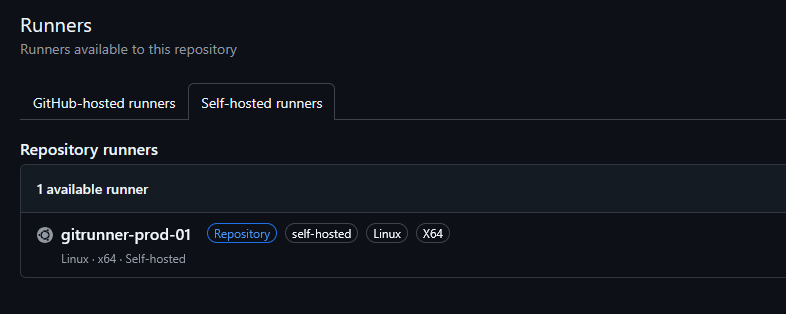
- Instálalo como un servicio de systemd para que sobreviva a los reinicios:
# Instalar e iniciar el servicio en segundo plano
sudo ./svc.sh install
sudo ./svc.sh start
Tu runner ahora aparecerá como “Idle” (con un punto verde) en los ajustes de tu repositorio de GitHub, listo para procesar trabajos incluso después de reiniciar el contenedor.
Paso 2: Orquestando la Lógica del “Fallback” (Plan B)
Aquí es donde ocurre la magia de la Alta Disponibilidad (HA). No basta simplemente con cambiar nuestro viejo runs-on: ubuntu-latest por runs-on: self-hosted.
Si mi proveedor de internet se cae, o si estoy realizando mantenimiento en mi clúster Proxmox, mi Runner local estará fuera de línea. Si hago un push de código durante esa ventana, el pipeline fallará. Para lograr una verdadera resiliencia empresarial, debemos diseñar un mecanismo de Fallback.
Queremos que el pipeline intente primero con el Homelab (Prioridad 1, costo cero), y solo si el Homelab es inalcanzable, falle hacia la nube de GitHub (Prioridad 2, consume minutos).
Para lograr un estado de “Alta Disponibilidad Real” (True HA), debemos asegurar que nuestro pipeline pueda detectar fallos instantáneamente y conmutar a la nube sin intervención humana. Esto se logra eliminando la bandera continue-on-error (para que GitHub detecte el fallo correctamente) e implementando un límite de timeout-minutes: 5, lo que evita que el pipeline se quede en un limbo de espera (“Queued”) si el runner local está fuera de línea.
El Código del Pipeline Híbrido
Así es como orquestamos esa lógica usando trabajos aislados dentro de nuestro archivo .github/workflows/deploy.yml:
name: Deploy MXLIT to VPS
on:
push:
branches:
- main
paths:
- 'mxlit-site/mxlit-blog/**'
schedule:
- cron: '0 * * * *'
jobs:
# Prioridad 1: Hacer el trabajo pesado usando mi Homelab en Proxmox
deploy-homelab:
runs-on: self-hosted
# Fail fast if the self-hosted runner is offline or hangs
timeout-minutes: 5
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: true
fetch-depth: 0
- name: Setup Hugo & Build
uses: peaceiris/actions-hugo@v3
with:
hugo-version: 'latest'
extended: true
- run: hugo --source mxlit-site/mxlit-blog --minify
- name: Deploy via Rsync to VPS
uses: easingthemes/ssh-deploy@main
env:
SSH_PRIVATE_KEY: ${{ secrets.FTP_SSH_KEY }}
REMOTE_HOST: ${{ secrets.FTP_SERVER }}
REMOTE_USER: ${{ secrets.FTP_USERNAME }}
REMOTE_PORT: ${{ secrets.FTP_PORT }}
SOURCE: 'mxlit-site/mxlit-blog/public/'
TARGET: '/home/deploy-mxlit/mxlit-site/public/'
ARGS: "-rltgoDzvO --delete"
# Prioridad 2: Recuperación ante Desastres mediante la Nube de GitHub
deploy-github-cloud:
runs-on: ubuntu-latest
needs: deploy-homelab
# CRÍTICO: Este trabajo SOLO se ejecuta si el homelab falló o no respondió
if: failure()
steps:
- name: Checkout repository
uses: actions/checkout@v4
with:
submodules: true
fetch-depth: 0
- name: Setup Hugo & Build
uses: peaceiris/actions-hugo@v3
with:
hugo-version: 'latest'
extended: true
- run: hugo --source mxlit-site/mxlit-blog --minify
- name: Deploy via Rsync to VPS
uses: easingthemes/ssh-deploy@main
env:
SSH_PRIVATE_KEY: ${{ secrets.FTP_SSH_KEY }}
REMOTE_HOST: ${{ secrets.FTP_SERVER }}
REMOTE_USER: ${{ secrets.FTP_USERNAME }}
REMOTE_PORT: ${{ secrets.FTP_PORT }}
SOURCE: 'mxlit-site/mxlit-blog/public/'
TARGET: '/home/deploy-mxlit/mxlit-site/public/'
ARGS: "-rltgoDzvO --delete"
Comprendiendo el Flujo del Fallback
La elegancia de esta estructura radica en la remoción intencional de la bandera continue-on-error, combinada con la condición if: failure() en el segundo trabajo.
- Escenario A (El Camino Feliz): Hago push. Mi runner de Proxmox está en línea. Intercepta el trabajo, usa su RAM/CPU local para compilar, usa Rsync para enviar el HTML a mi VPS en Francia y reporta “Success”. El Trabajo 2 detecta el éxito, se da cuenta de que
if: failure()es falso y salta su ejecución. Costo: 0 Minutos de GitHub. - Escenario B (Desastre): Una tormenta corta la luz en mi Homelab. Hago push desde mi laptop en una cafetería. GitHub intenta contactar al runner
self-hosted, pero este no responde. Debido a que configuramos untimeout-minutes: 5, el Trabajo 1 “Falla” rápidamente. El Trabajo 2 evalúaif: failure(), ve que es verdadero, instancia instantáneamente un contenedor de Microsoft Azure (ubuntu-latest), compila mi código, despliega a Francia y salva el día. Costo: 1 Minuto de GitHub.
Para verificar que todo esté funcionando como se espera, puedes revisar el estado de la ejecución en el repositorio de GitHub.
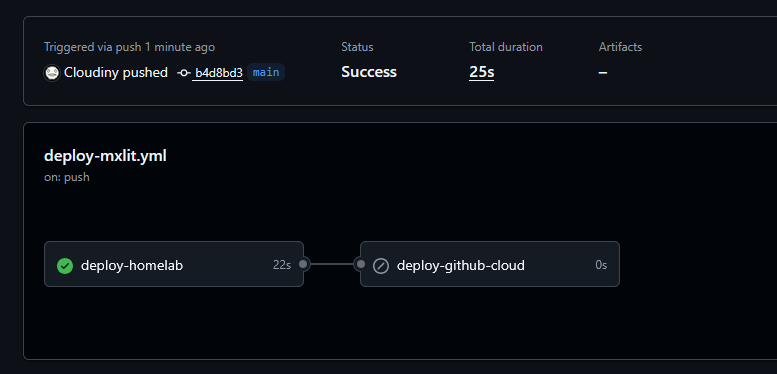
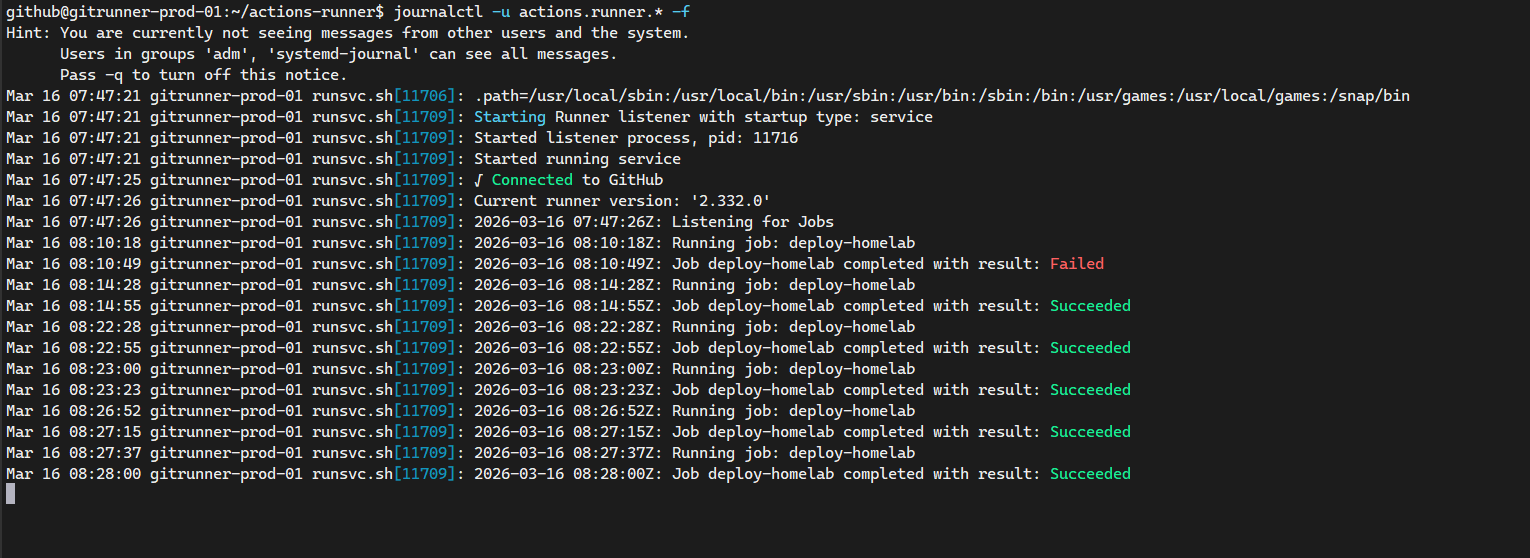
También puedes verificar los logs del self-hosted runner directamente en tu clúster Proxmox ejecutando el siguiente comando:
journalctl -u actions.runner.* -f
Paso 3: Mantenimiento Automatizado (Logrotate)
Para mantener ese nodo de Proxmox optimizado y evitar sorpresas con el almacenamiento del LXC a largo plazo, automatizar la limpieza de logs es un paso fundamental de infraestructura. El runner de GitHub es bastante ruidoso y genera un archivo de texto nuevo por cada trabajo y sesión en su carpeta _diag.
Aquí tienes los pasos para crear una regla de rotación que mantendrá solo el historial de los últimos 7 días, comprimiendo los archivos viejos para ahorrar espacio.
1. Crear el archivo de configuración
Vamos a crear un archivo dedicado para el runner dentro del directorio de logrotate. Ejecuta esto como root o usando sudo en tu terminal de Ubuntu:
# Create and edit the new logrotate configuration file
sudo nano /etc/logrotate.d/github-runner
2. Agregar las reglas de rotación
Pega el siguiente bloque de configuración dentro del editor. Nota que estoy usando un asterisco (actions-runner*) en la ruta para que, si en el futuro agregas más carpetas para otros repositorios dentro del usuario github, esta regla los cubra automáticamente a todos.
# Target the diagnostic logs for all runner instances under the github user
/home/github/actions-runner*/_diag/*.log {
# Rotate the logs daily
daily
# Do not output an error if the log file is missing
missingok
# Keep 7 days of backlogs
rotate 7
# Compress the rotated files (gzip by default)
compress
# Postpone compression of the previous log file to the next rotation cycle
delaycompress
# Do not rotate the log if it is empty
notifempty
# Switch to the github user and group to avoid permission issues
su github github
# Create new empty log files with these specific permissions
create 0644 github github
}
Guarda los cambios y sal del editor (Ctrl+O, Enter, Ctrl+X en nano).
3. Verificar la sintaxis (Dry Run)
Siempre es buena práctica probar que logrotate entienda la regla sin problemas antes de dejarlo en piloto automático. Puedes ejecutar un “simulacro” con el siguiente comando:
# Run a debug/dry-run test to verify the configuration syntax
sudo logrotate -d /etc/logrotate.d/github-runner
Si todo está correcto, verás en la salida de la terminal cómo logrotate lee la ruta, detecta los archivos .log actuales y te explica qué haría con ellos (sin borrar ni comprimir nada realmente). A partir de este momento, el demonio de cron de Ubuntu se encargará de ejecutar esta regla silenciosamente todos los días.
Conclusión
Al integrar un Self-Hosted Runner en tu flujo de trabajo, recuperas la propiedad sobre tu potencia de procesamiento y eliminas la ansiedad de las cuotas artificiales. Más importante aún, al envolver ese runner local en una configuración de fallback en la nube, creas un pipeline de despliegue inmatable y de alta disponibilidad.
Esto ya no es solo un script copiando archivos; es un sistema inteligente y auto-curable digno de un entorno Enterprise.