
Desplegar un clúster virtual de Dell EMC Isilon (OneFS) en tu entorno de laboratorio con Proxmox es una excelente manera de probar caracterÃsticas empresariales como SyncIQ, SmartPools o SmartConnect. Sin embargo, este simulador tiene un “Talón de Aquiles” crÃtico cuando se ejecuta en hipervisores de uso general: la susceptibilidad a la corrupción del sistema de archivos ante apagones repentinos.
Aquà te explico exactamente por qué ocurre esto y cómo solucionarlo ajustando las polÃticas de almacenamiento en Proxmox.
El Problema: La Ausencia de NVRAM FÃsica
En un entorno de producción, los nodos fÃsicos de Isilon dependen fuertemente de una tarjeta NVRAM (Non-Volatile RAM) respaldada por una baterÃa. Esta memoria actúa como un journal ultrarrápido y seguro. Cualquier transacción de escritura entra primero a la NVRAM; si hay un corte de energÃa, la baterÃa asegura que los datos se guarden en el disco una vez que vuelva la luz.
El problema en el entorno virtual: El simulador de OneFS no tiene hardware fÃsico de NVRAM, por lo que emula este comportamiento reservando una partición directamente en los discos virtuales (tus archivos .qcow2).
Por defecto, hipervisores como Proxmox utilizan la memoria RAM del host (tu servidor) para hacer caché de las escrituras y mejorar el rendimiento. Si apagas la máquina virtual de golpe (usando la función Stop o si sufres un corte de luz), los datos que estaban en la caché de Proxmox nunca llegan a escribirse fÃsicamente en tu SSD.
Al reiniciar, OneFS detecta que su “NVRAM virtual” está corrupta, arroja un error crÃtico de GEOM panic y el nodo queda completamente inoperable.
Contexto Adicional: Integridad de Datos vs Velocidad
Es vital comprender que la NVRAM no es solo para velocidad, sino el pilar de la integridad de datos en arquitecturas de almacenamiento distribuido. En un clúster de Isilon, los journals se espejean entre nodos. En un entorno virtual sin persistencia inmediata garantizada, un " Hard Stop" puede dejar el clúster en un estado inconsistente donde los nodos no logran ponerse de acuerdo sobre qué datos se confirmaron y cuáles no, resultando en la pérdida total del pool.
La Solución: Forzar Escrituras SÃncronas (Write Through)
Para proteger la integridad del clúster y emular la persistencia inmediata de una NVRAM real, debemos obligar a Proxmox a que elimine el almacenamiento en caché del host para esos discos especÃficos.
La solución es cambiar la polÃtica de caché de los discos virtuales a Write through (o Direct sync). Este modo obliga al hipervisor a escribir cada bloque de datos directamente en el disco de almacenamiento fÃsico subyacente antes de enviarle la confirmación de “éxito” a la máquina virtual de OneFS.
Cómo aplicarlo desde la interfaz web de Proxmox (GUI)
Si tienes pocos discos, puedes hacerlo manualmente antes de encender el nodo:
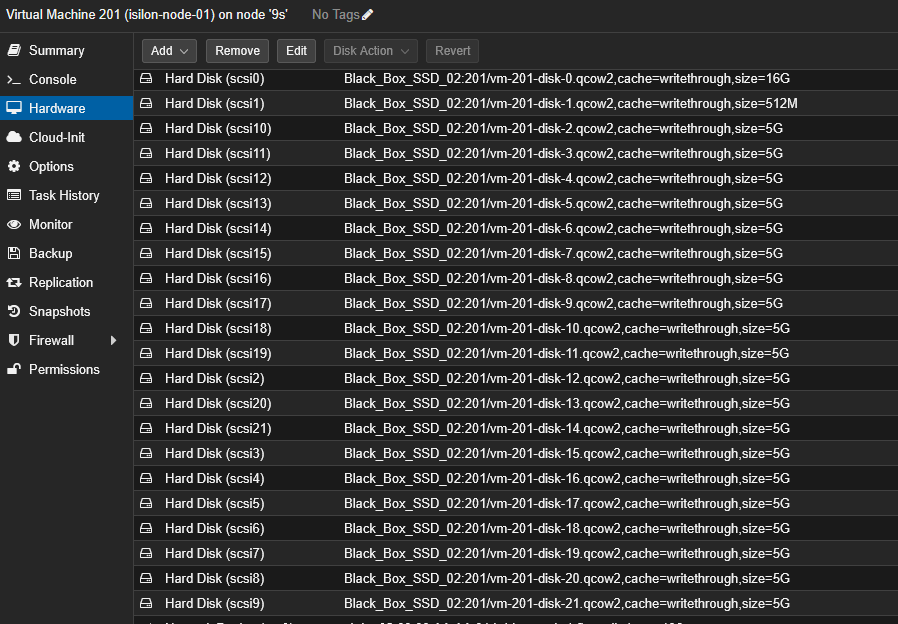
- Selecciona tu máquina virtual de OneFS y ve a la pestaña Hardware.
- Haz doble clic sobre cada uno de los discos duros (
scsi0,scsi1, etc.). - En la ventana de configuración, localiza el menú desplegable Cache.
- Cámbialo de Default (No cache) a Write through.
- Guarda los cambios. (Recuerda que la VM debe estar completamente apagada para que el hipervisor aplique el cambio).
Cómo aplicarlo de forma masiva por consola (CLI)
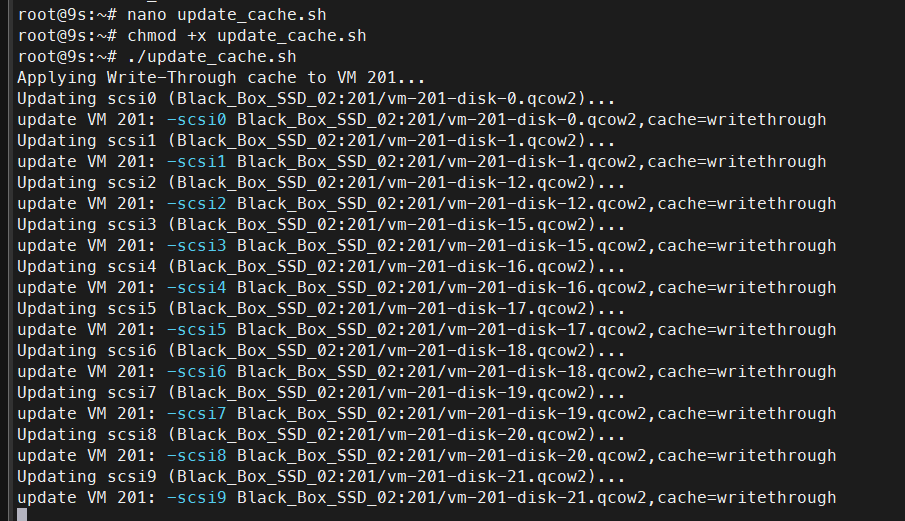
Dado que un nodo virtual completo de Isilon utiliza 22 discos virtuales, hacerlo uno por uno no es eficiente. Puedes usar el siguiente script directamente en la shell de tu nodo Proxmox para actualizar todos los discos de un solo golpe.
#!/bin/bash
# Define the target VM ID for the OneFS node
VMID=201
echo "Applying Write-Through cache to all disks on VM $VMID..."
# Loop through all 22 possible SCSI devices
for i in {0..21}; do
# Extract the current volume path from the VM configuration
VOL=$(qm config $VMID | grep "^scsi${i}:" | awk '{print $2}' | cut -d',' -f1)
# If the volume exists, overwrite its configuration to enforce writethrough cache
if [ ! -z "$VOL" ]; then
echo "Updating scsi${i} ($VOL) to use Write-Through cache..."
qm set $VMID --scsi${i} "${VOL},cache=writethrough"
fi
done
echo "Cache update process completed successfully!"
Prueba de Fuego: Validando la Resiliencia de tu Nodo
La mejor manera de confiar en tu infraestructura es rompiéndola a propósito en un ambiente controlado. Para comprobar que el ajuste de caché está funcionando correctamente y protegiendo tu clúster, realizaremos una prueba de apagado abrupto (Hard Stop).
Paso 1: La Red de Seguridad (Snapshot) Antes de desconectar el cable virtual, vamos a protegernos tomando un snapshot de la máquina virtual en Proxmox.
- Ve a tu VM de Isilon > Snapshots > Take Snapshot.
- Nómbralo algo como “Pre-Hard-Stop”. Esto te garantiza que, si por alguna razón el hardware subyacente fallara (por ejemplo, si la memoria DRAM interna de tu SSD no vacÃa a tiempo), puedas restaurar el nodo a su estado limpio en segundos.
Paso 2: El Corte de EnergÃa Asegúrate de que el nodo de Isilon haya arrancado por completo y muestre el prompt de login: en la consola.
- En la interfaz web de Proxmox, selecciona la máquina virtual y presiona el botón Stop sin piedad (no uses Shutdown). Esto matará el proceso de la VM de inmediato, simulando una pérdida total de energÃa en el servidor.
Paso 3: El Reinicio y la Validación
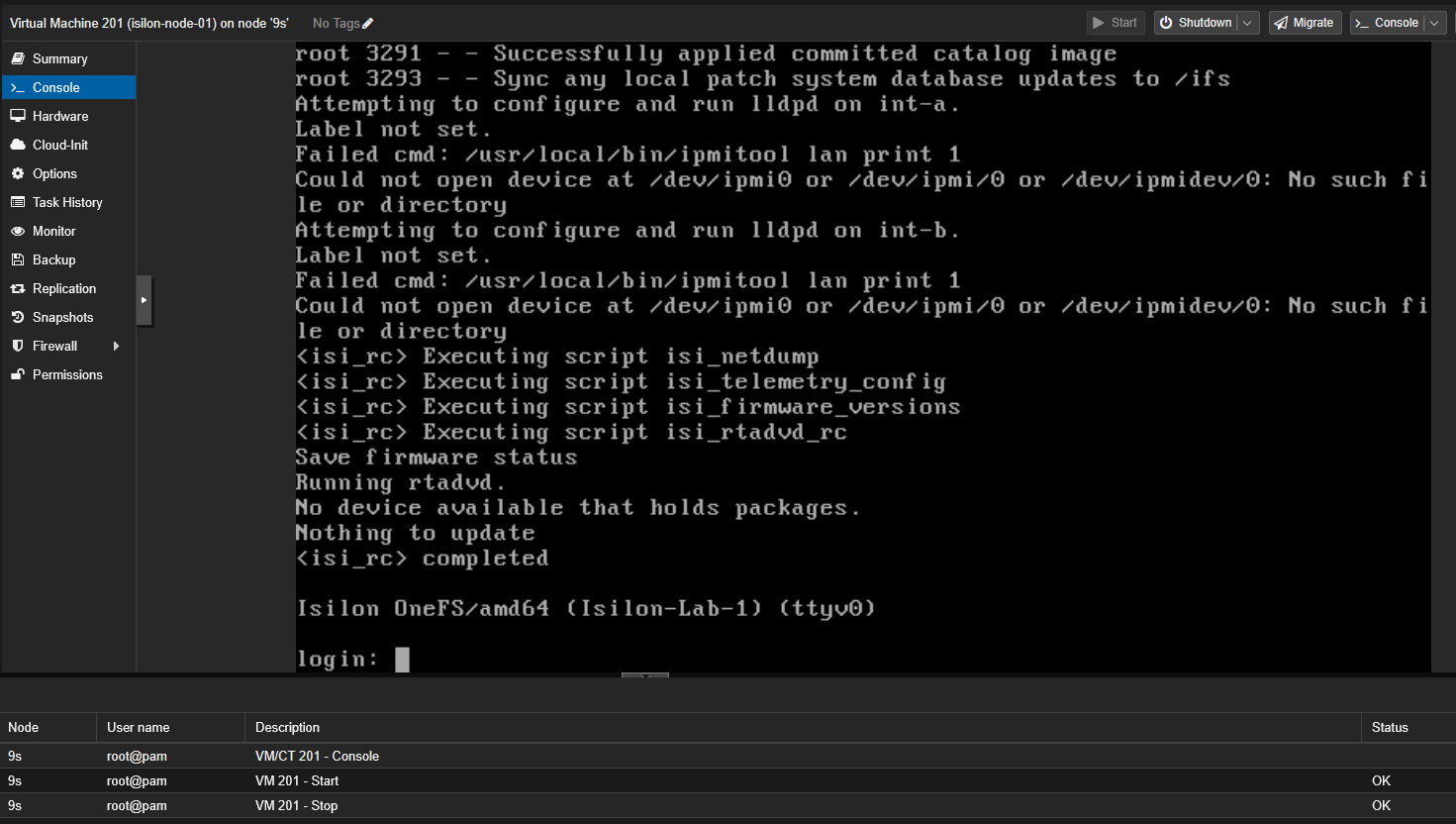
- Vuelve a encender la VM (Start) y abre la consola VNC inmediatamente.
- Presta mucha atención a la secuencia de arranque de FreeBSD. Si el sistema pasa la fase de
Executing GEOM bootdisk startup...sin arrojar el error crÃticoGEOM start failed, y continúa cargando hasta entregarte de nuevo el prompt delogin:, ¡felicidades!
Conclusión y Mejores Prácticas
Implementar la caché Write through funcionará como un excelente paracaÃdas de emergencia contra corrupciones de GEOM si tu servidor de virtualización sufre un reinicio inesperado.
No obstante, la regla de oro se mantiene: la forma oficial y segura de apagar tu clúster en el laboratorio siempre será conectándote por SSH a cualquier nodo y ejecutando el comando de apagado seguro:
isi cluster shutdown
Esto le dará tiempo a OneFS de vaciar sus procesos, detener los servicios SMB/NFS y guardar su propio estado antes de enviar la señal de apagado al hipervisor. Sin NVRAM fÃsica, tus datos están a merced de la latencia de commit de tus discos locales.
.