
Integrating additional nodes into an Isilon cluster is one of the most rewarding processes in the OneFS architecture. Once the first node is operational, expanding capacity and performance is nearly automatic.
In this guide, we detail the steps to join Node 2 (and subsequent nodes) to our lab cluster in Proxmox.
Requisitos Previos (Checklist Rápido)
Antes de presionar el botón de inicio, asegúrate de que la máquina virtual (ej. VM 202) cumple estrictamente con la arquitectura definida:
Discos: 22 discos SCSI inyectados, con la política de caché configurada en
Write throughpara proteger la “NVRAM virtual”.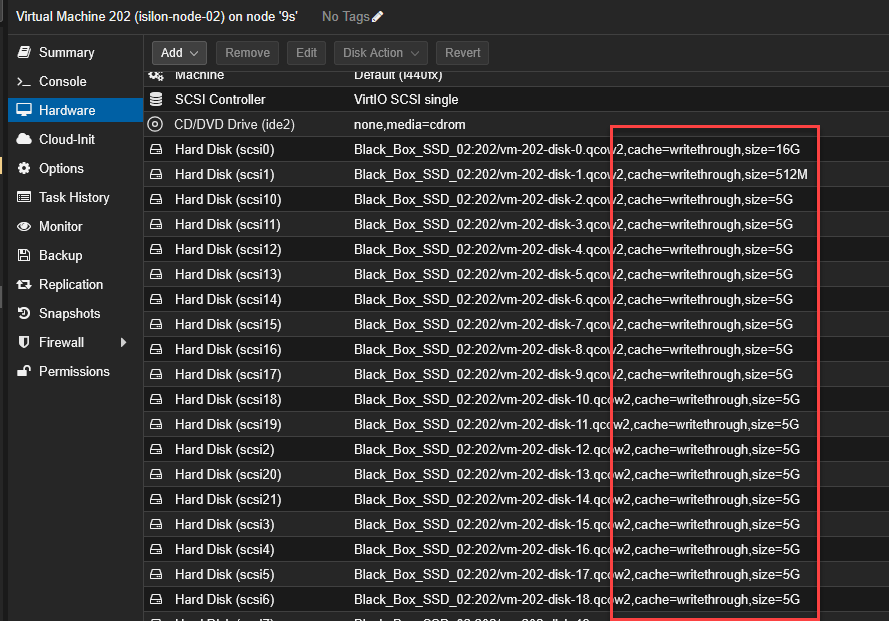
Arranque: El orden de booteo (Boot Order) tiene a
scsi0habilitado y como primera opción.
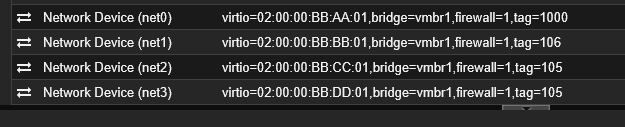
Redes: Cuatro interfaces asignadas (Management, SMB y Backend), respetando las direcciones MAC y los VLAN tags (100, 106, 105, 105) correspondientes al Nodo 2.
Paso 1: Encendido e Inicialización del Sistema
- En Proxmox, selecciona la VM del Nodo 2 y haz clic en Start.
- Abre la consola (VNC) inmediatamente. Verás la secuencia de arranque de FreeBSD detectando la topología SCSI.
- Espera hasta que aparezca el menú principal del Configuration Wizard.
Paso 2: Unirse al Clúster Existente
La integración de nodos secundarios es sumamente ágil gracias a la red de Backend.
Cuando se te pida formatear los drives, escribe
yes.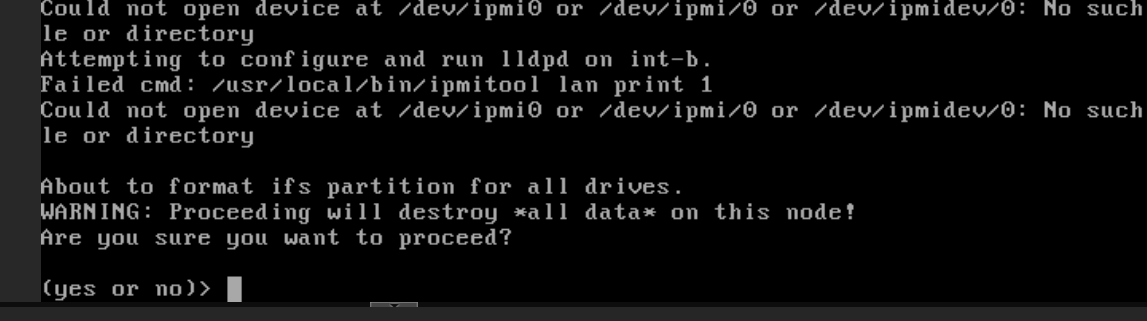
En el menú del asistente, selecciona la opción
2(Join an existing cluster).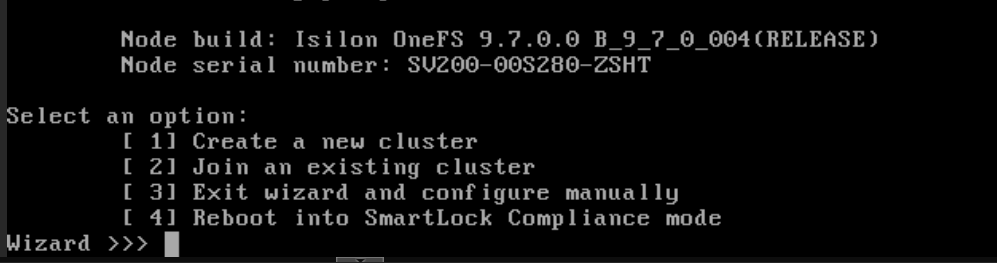
El sistema buscará a través de la interfaz Backend (VLAN 1000). En unos segundos, detectará tu clúster activo (ej.
Isilon-Lab).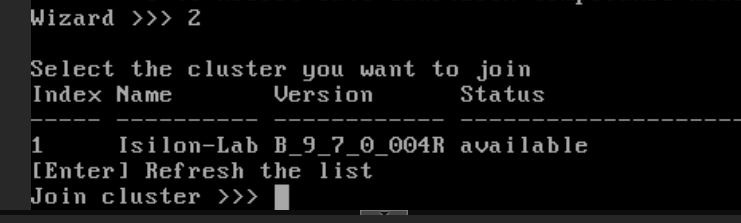
Escribe
1para confirmar la unión al clúster detectado.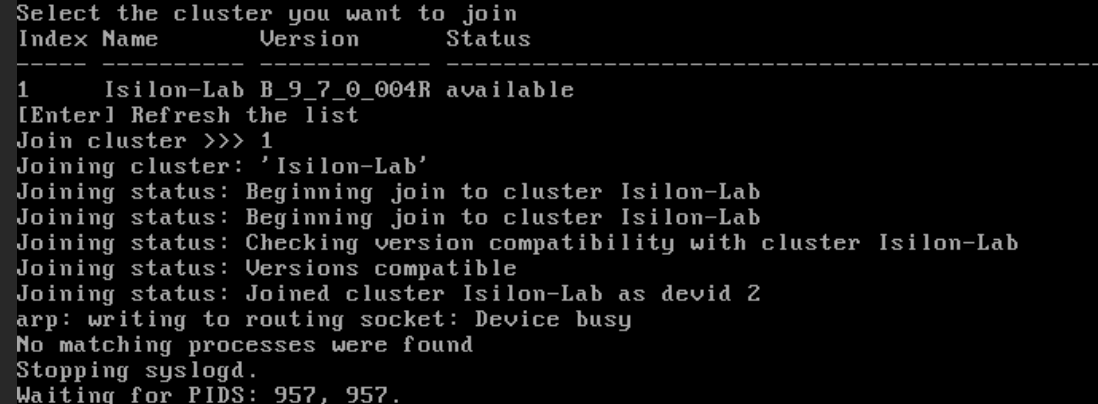
Paso 3: Sincronización Automática
Al confirmar, el Nodo 2 cede su administración al clúster lógico:
- Formateará los discos de datos restantes para sumarlos al storage pool global.
- Sincronizará el journal, configuraciones de red y credenciales desde el Nodo 1.
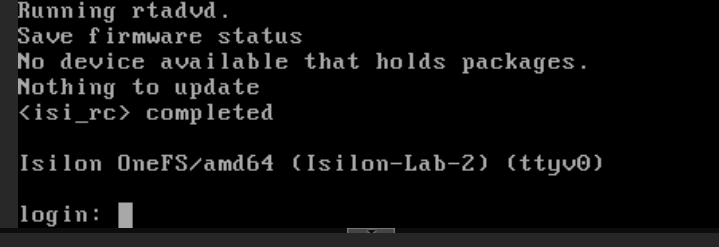
- Sabrás que ha concluido exitosamente cuando aparezca el prompt:
Isilon-Lab-2 login:.
Paso 4: Verificación del Estado
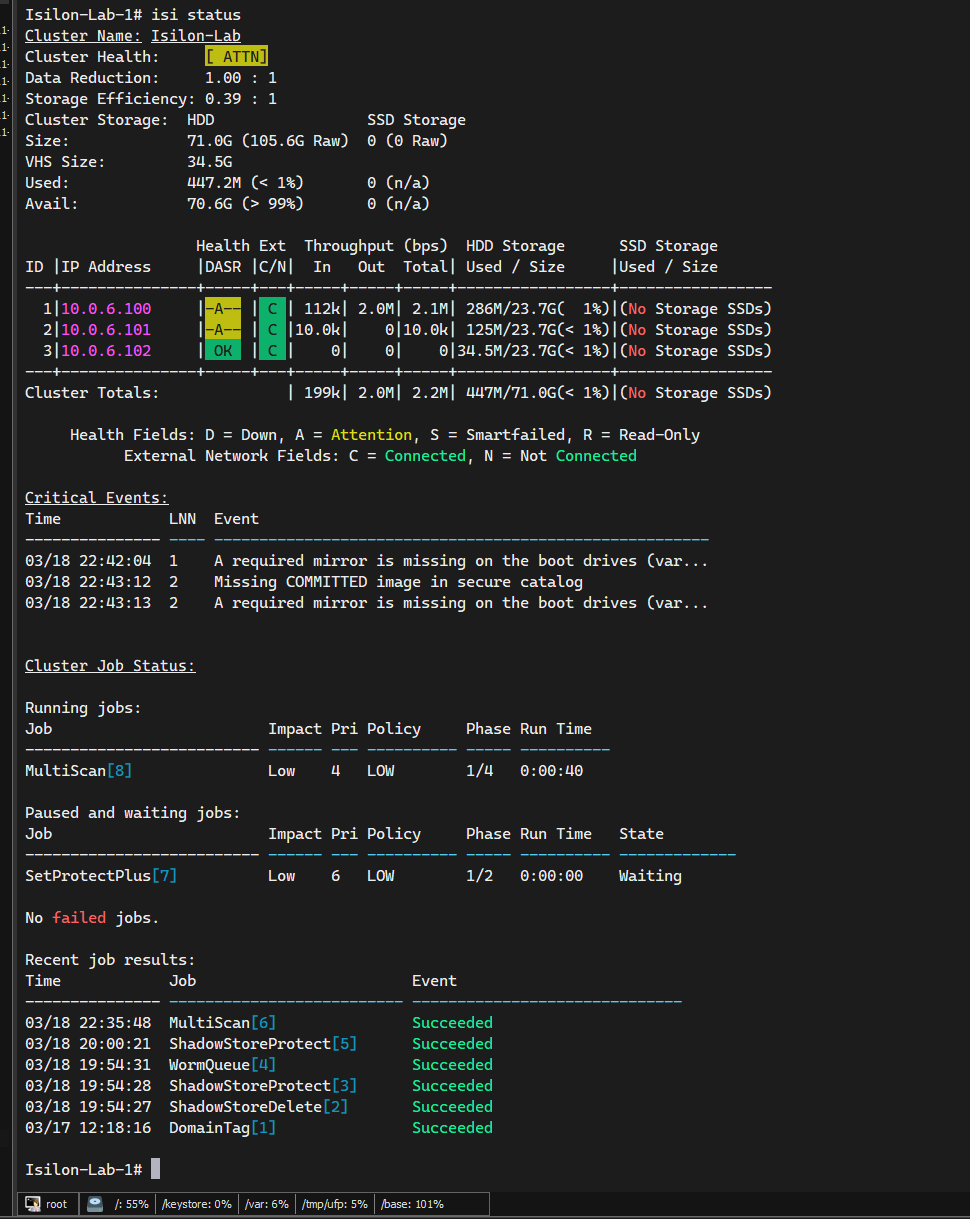
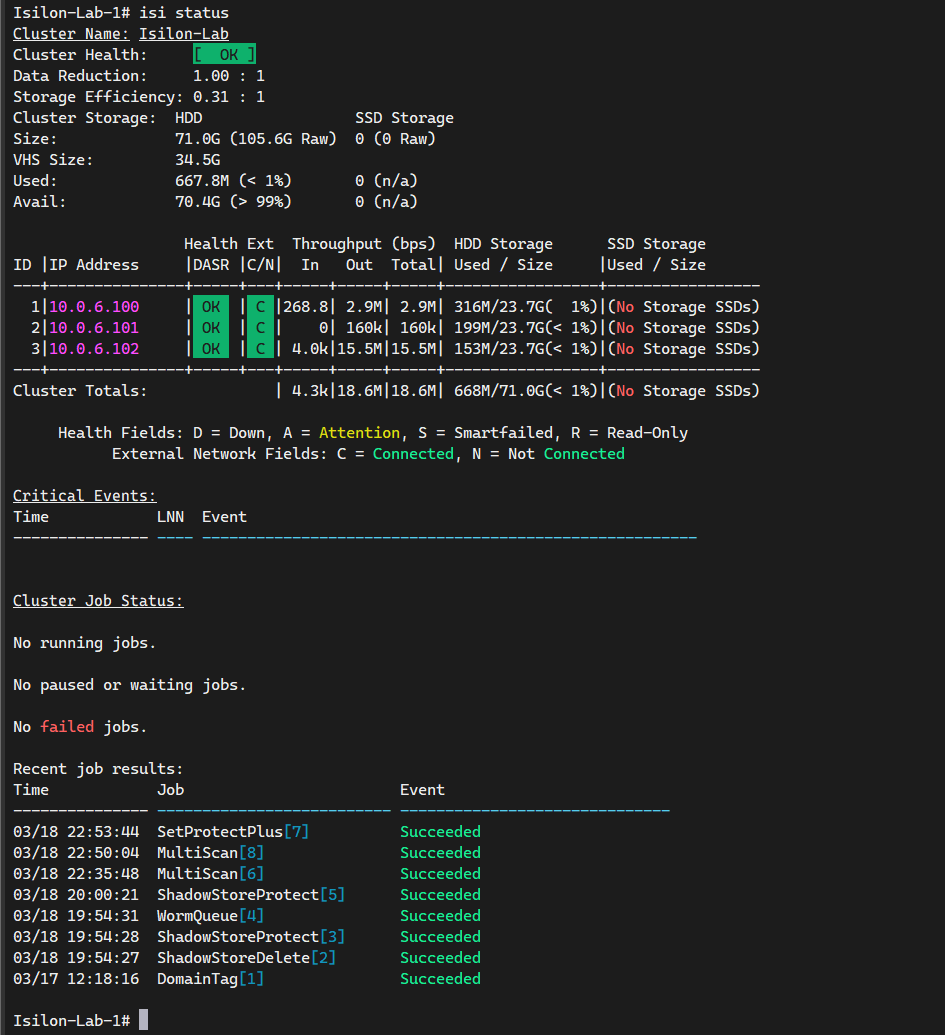
Desde la consola del Nodo 1 (o por SSH), ejecuta:
isi status
Deberías ver dos nodos activos en estado [ OK ] o Healthy.
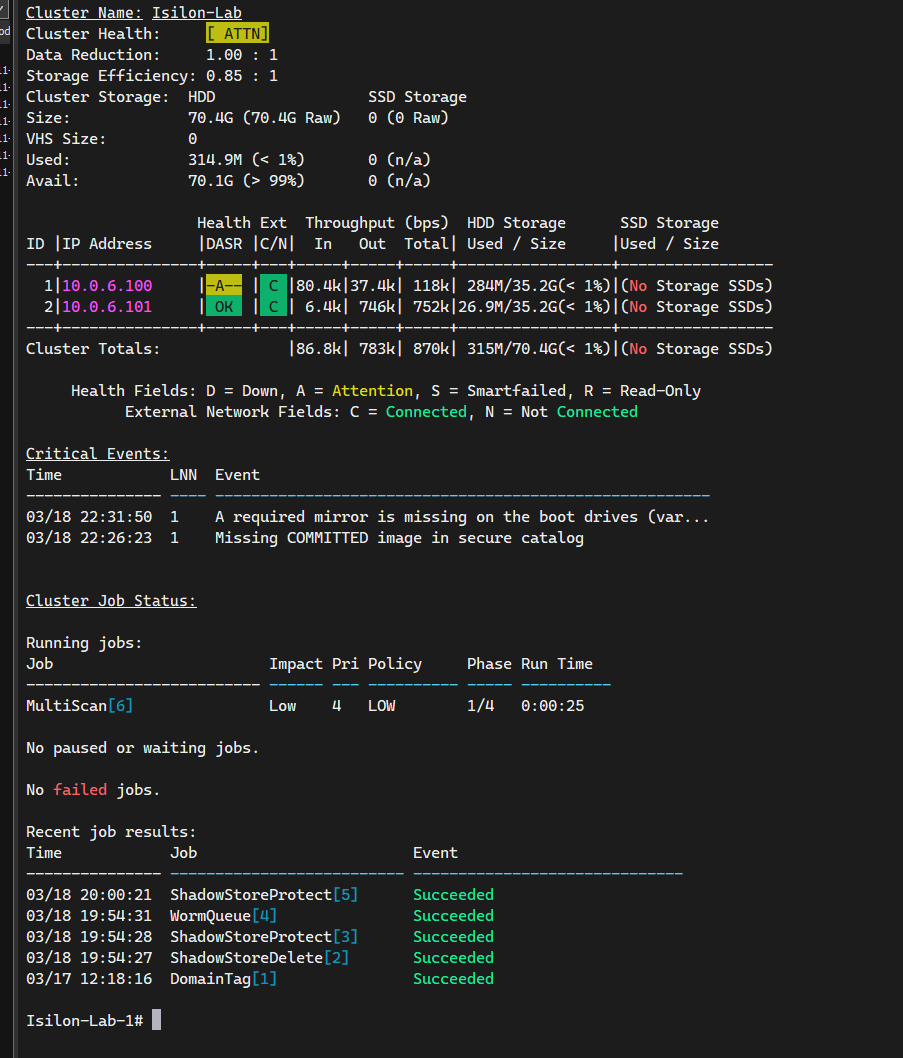
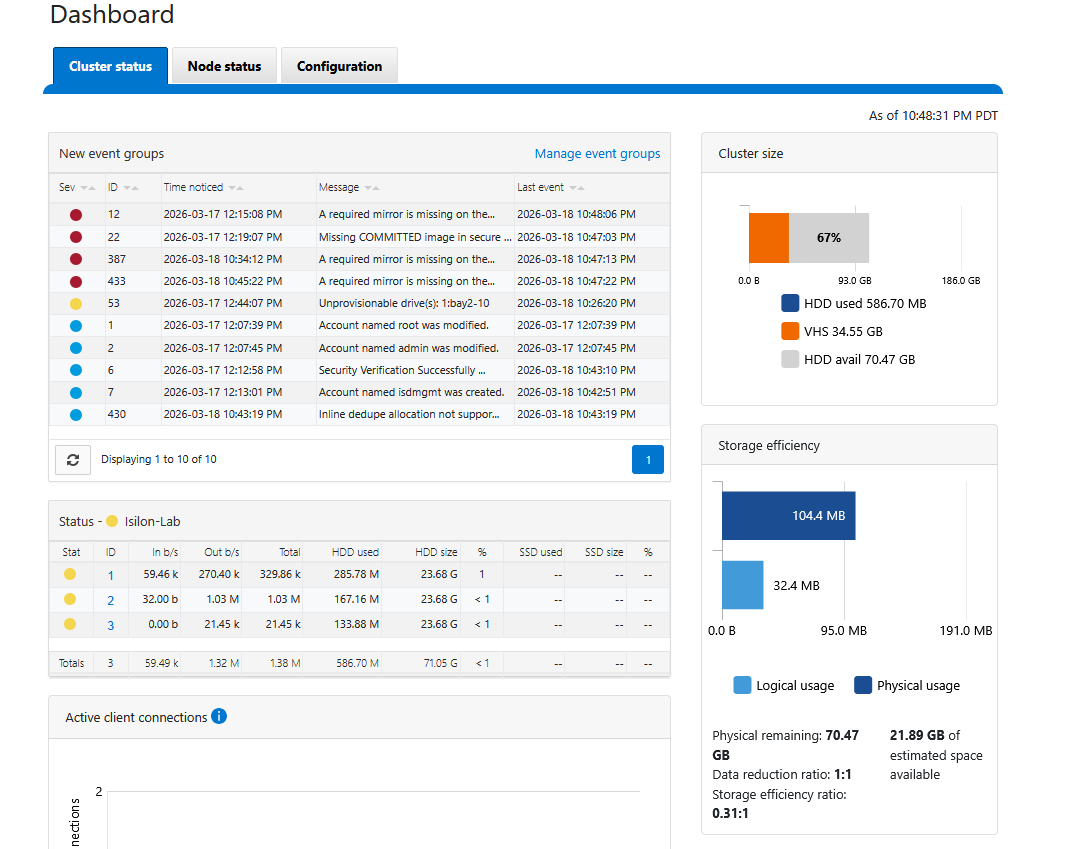
También puedes entrar a la WebUI usando las IPs de cualquiera de los nodos (puerto 8080) y verás el clúster consolidado en el Dashboard.
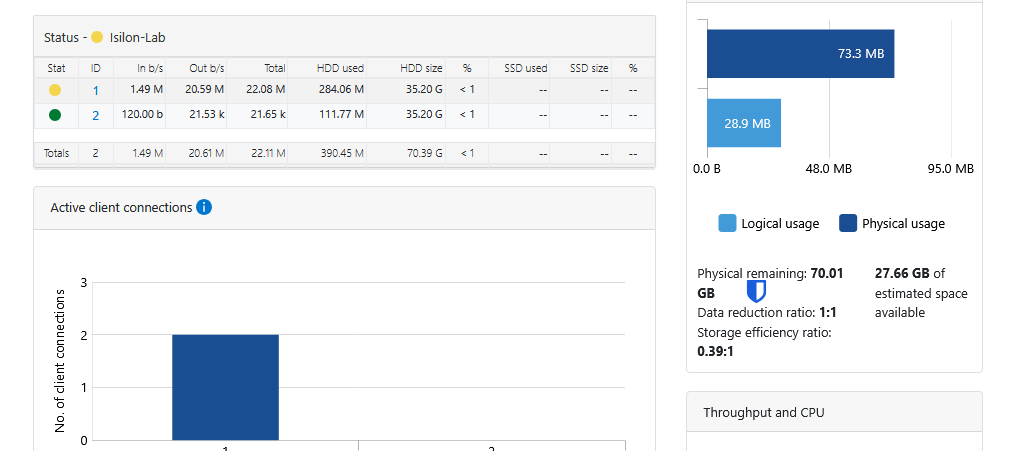
El Job Engine en Acción: MultiScan
Una vez que has agregado el Nodo 2 (y subsecuentemente el Nodo 3), notarás actividad inmediata en el Job Engine. Es normal ver el trabajo MultiScan en estado de ejecución (Running).
Este proceso es fundamental: el “cerebro” de OneFS ha detectado los nuevos discos y el nuevo nodo, y ha comenzado automáticamente a rebalancear el sistema de archivos distribuido (/ifs). OneFS está redistribuyendo los datos existentes y extendiendo la protección de paridad (Erasure Coding) a través de todo el nuevo hardware disponible en tiempo real. Esta es la verdadera potencia del almacenamiento Scale-Out ocurriendo ante tus ojos.
Analizando el Estado de “Atención” (ATTN)
Es normal que el simulador marque [ ATTN ] con una “A” amarilla. Son falsos positivos del entorno virtual:
- Mirror missing on boot drives: El simulador carece del espejo físico de discos de sistema que OneFS espera.
- Missing COMMITTED image: Advertencia inofensiva sobre firmas de firmware de hardware Dell real que no existe en la VM.
Ambos eventos son cosméticos y no degradarán el rendimiento de tu laboratorio.
Limpieza de Eventos: Alcanzando el Estado “Healthy”
Para limpiar estos falsos positivos y asegurar que tu dashboard refleje un estado saludable [ OK ], puedes resolver los eventos manualmente a través de la WebUI:
Ingresa a la WebUI (
https://<node-ip>:8080).Dirígete a Cluster Management > Events.
Selecciona los eventos activos relacionados con los espejos de booteo y catálogos de firmware.
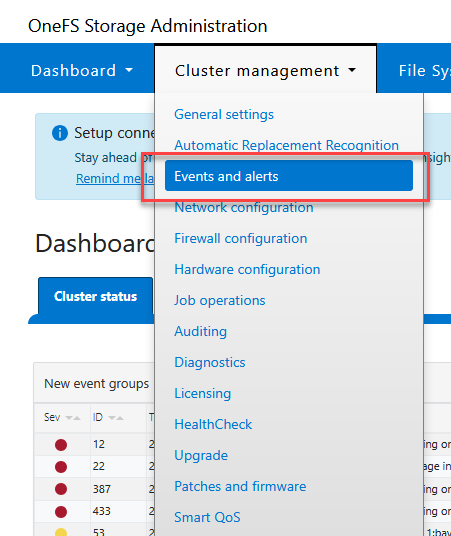
Marca estos eventos como “Resolved” o “Ignored”.
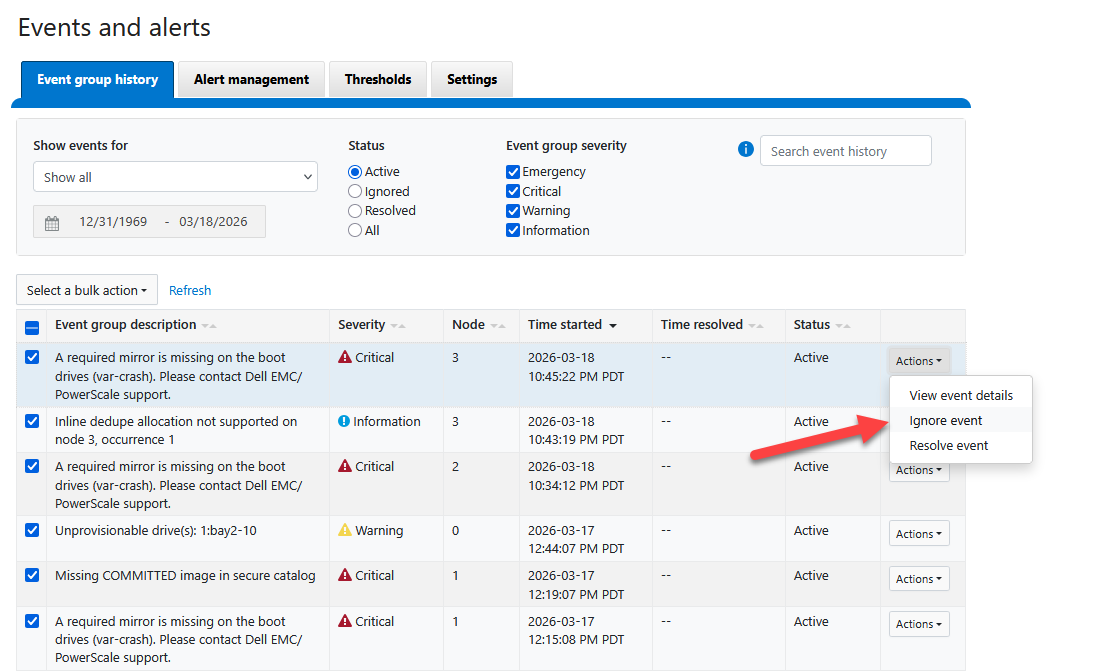
Una vez resueltos, el monitor de salud de OneFS actualizará su estado. Si revisas el dashboard ahora, deberías ver el clúster en un estado verde perfecto.
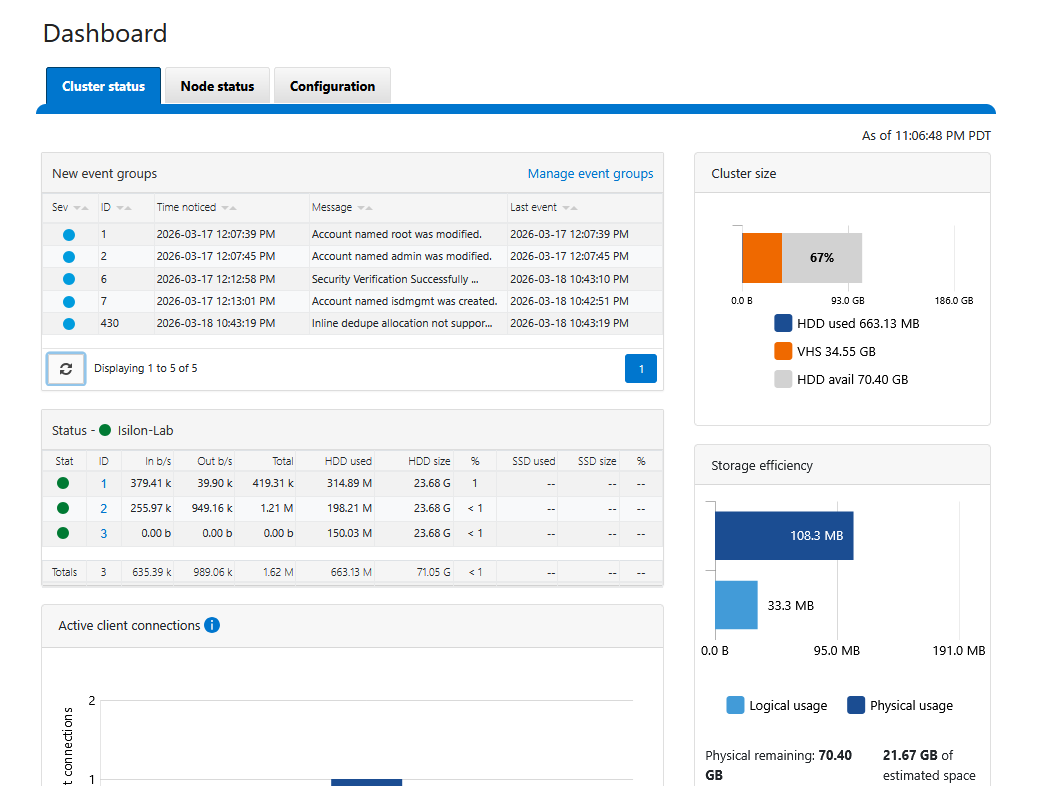
Conclusión y Mejores Prácticas
Expandir un clúster de Isilon es un proceso trivial desde el punto de vista del administrador, pero increíblemente complejo tras bambalinas. Al unir el Nodo 2, hemos duplicado no solo la capacidad de almacenamiento, sino también el ancho de banda agregado y la resiliencia del sistema.
Puntos Clave para el Administrador:
- Monitoreo del Job Engine: Siempre verifique que el trabajo
MultiScanoAutoBalancetermine satisfactoriamente antes de realizar cambios mayores en la red o agregar más nodos. - Quórum Estricto: Recuerde que en clústers pequeños, la salud de cada nodo es crítica para mantener el quórum de escritura.
- Próximos Pasos: Con el quórum de nodos establecido, el siguiente paso lógico es configurar las SmartConnect zones para balancear el tráfico de los clientes entre todos los nodos de forma transparente.
Esta arquitectura de expansión lineal asegura que tu entorno de almacenamiento crezca al ritmo de tus necesidades de datos sin tiempos de inactividad ni migraciones complejas.
.