
A medida que el volumen de datos crece, un porcentaje significativo se convierte en información “fría” (cold data) — archivos históricos que rara vez se consultan. Mantener estos datos en el almacenamiento primario de alto rendimiento resulta ineficiente a nivel de costos.
Para solucionar esto, OneFS integra CloudPools, una función de tiering (estratificación) que permite mover bloques de datos inactivos hacia un almacenamiento de objetos externo, como Amazon S3, Azure Blob o un ECS local. Al realizar el movimiento, OneFS deja un archivo de referencia (SmartLink o stub) en el sistema de archivos local. Para los usuarios conectados vía SMB o NFS, el archivo sigue apareciendo en su ubicación original; si intentan abrirlo, el clúster lo recupera de la nube de forma transparente.
En esta guía, configuraremos CloudPools para archivar datos antiguos hacia un bucket de Amazon S3.
Requisitos Previos
Antes de configurar OneFS, se requiere lo siguiente en la infraestructura de nube:
- Un Bucket de Amazon S3 dedicado para telemetria de Isilon.

- Un usuario de IAM (Identity and Access Management) con permisos de lectura/escritura sobre ese bucket.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowBucketManagement",
"Effect": "Allow",
"Action": [
"s3:ListAllMyBuckets",
"s3:CreateBucket",
"s3:DeleteBucket"
],
"Resource": "*"
},
{
"Sid": "AllowIsilonBucketOperations",
"Effect": "Allow",
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation",
"s3:ListBucketMultipartUploads"
],
"Resource": "*"
},
{
"Sid": "AllowIsilonReadWriteDelete",
"Effect": "Allow",
"Action": [
"s3:PutObject",
"s3:GetObject",
"s3:DeleteObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": "*"
}
]
}
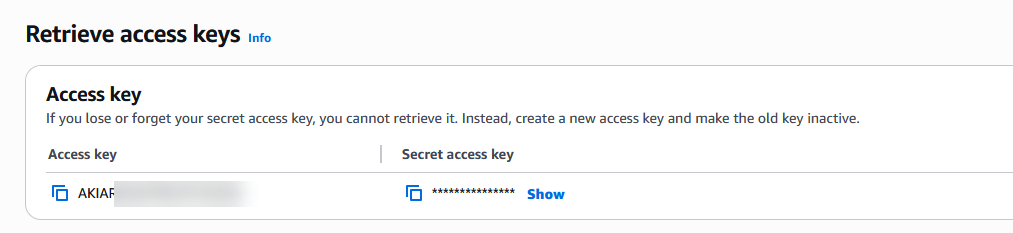
- Las credenciales programáticas del usuario IAM: Access Key ID y Secret Access Key.
Paso 1: Configurar la Cuenta de Almacenamiento en la Nube (Cloud Account)
El primer paso es registrar las credenciales de AWS dentro de Isilon para establecer la comunicación segura.
Vía WebUI:
- Ve a File System > Storage Pools > CloudPools.
- En la pestaña Cloud Accounts, haz clic en Create a Cloud Account.
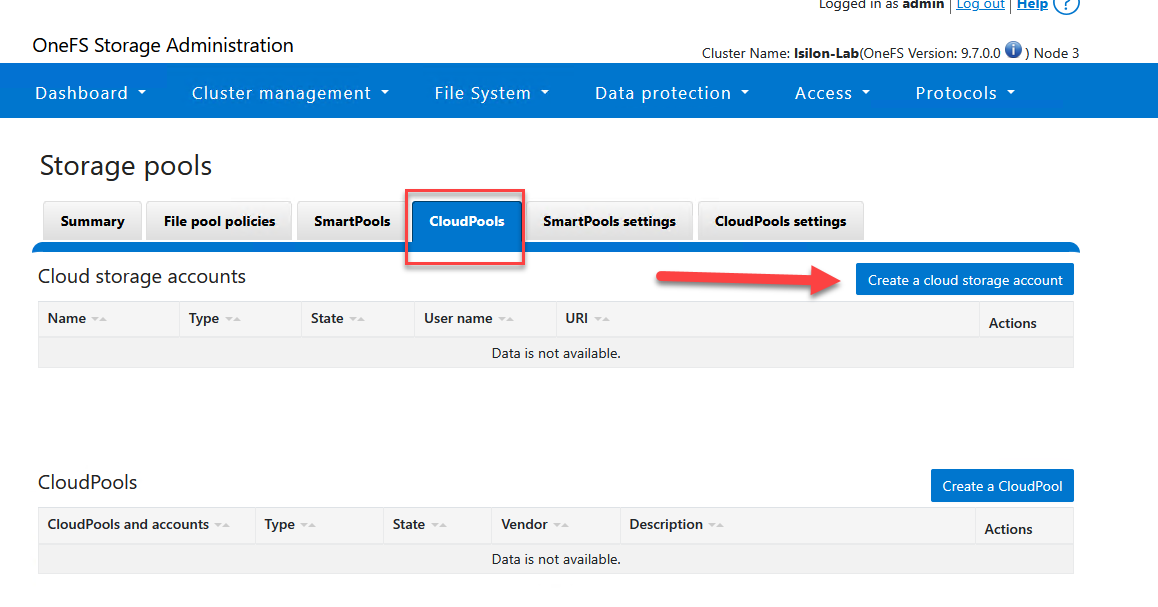
- Configura los parámetros de conexión:
Account Details
- Name or alias:
AWS_S3_Archive- Type: Selecciona
Amazon S3- URI: Ingresa el endpoint regional de S3 (ej.
https://s3.us-east-1.amazonaws.com)- User name (key): Ingresa el Access Key ID de tu usuario IAM en AWS.
- Key (secret key): Ingresa el Secret Access Key de AWS.
- Account ID: Ingresa el ID de tu cuenta de AWS (el número de 12 dígitos que aparece en tu consola, sin guiones).
- Telemetry reporting bucket: Ingresa el nombre exacto de tu bucket en S3 (ej.
isilon-lab-mxlit-test).
- Haz clic en Connect account para validar las credenciales y guardar.
Vía CLI:
# Create the AWS S3 cloud account using programmatic credentials
# Ensure you replace the placeholders with your actual AWS IAM and account details
isi cloud accounts create AWS_S3_Archive_CLI \
--type=s3 \
--uri=https://s3.us-east-1.amazonaws.com \
--account-username=<YOUR_AWS_ACCESS_KEY> \
--key=<YOUR_AWS_SECRET_KEY> \
--account-id=<YOUR_12_DIGIT_AWS_ACCOUNT_ID> \
--telemetry-bucket=<YOUR_S3_BUCKET_NAME>
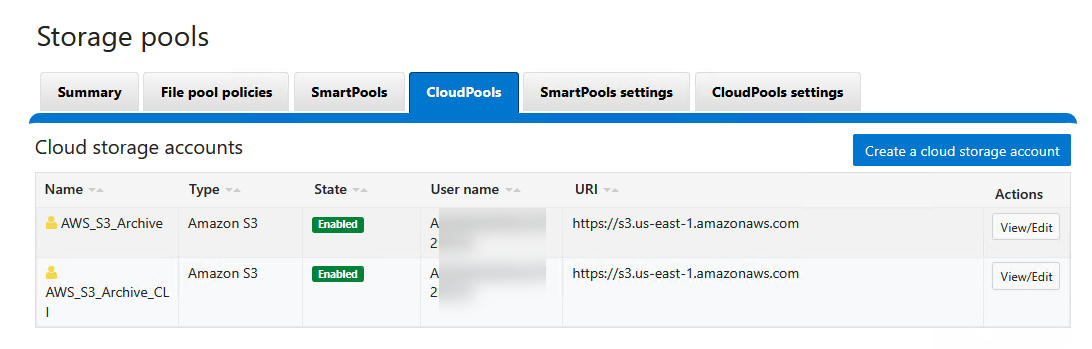
Paso 2: Crear el CloudPool
Una vez que la cuenta está conectada, debe asociarse a un “CloudPool”. Esto permite agrupar múltiples cuentas o definir configuraciones de encriptación y compresión antes de enviar los datos a la nube.
Vía WebUI:
- En el menú de CloudPools, ve a la pestaña CloudPools.
- Haz clic en Create a CloudPool.
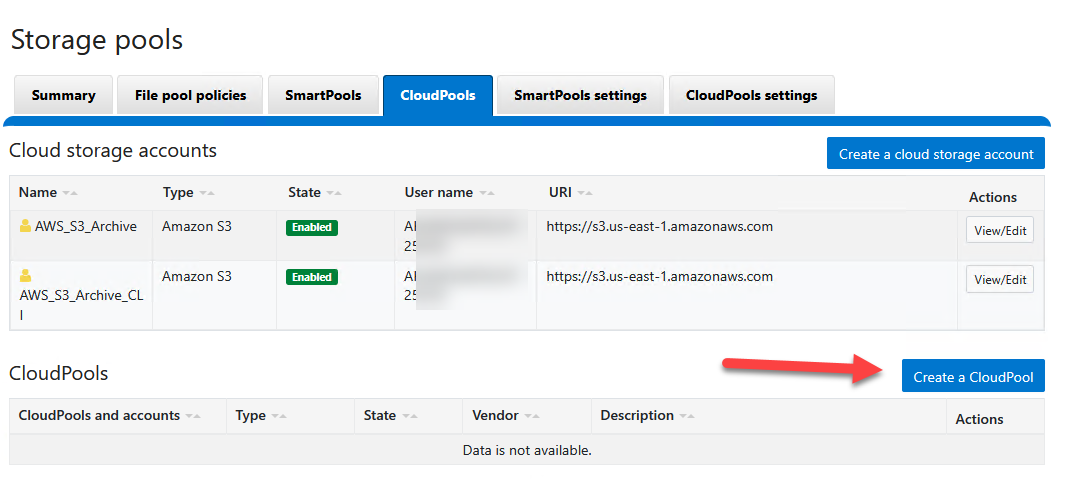
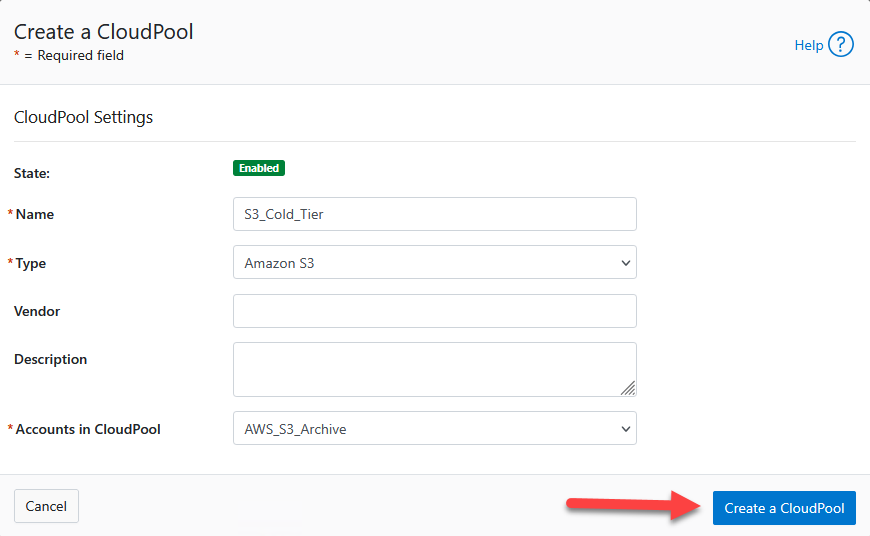
- Asigna un nombre:
S3_Cold_Tier. - En Type, selecciona
Amazon S3. - En Account, selecciona la cuenta creada en el paso anterior (
AWS_S3_Archive). - (Los campos Vendor y Description pueden quedar en blanco)
- Haz clic en Create CloudPool.
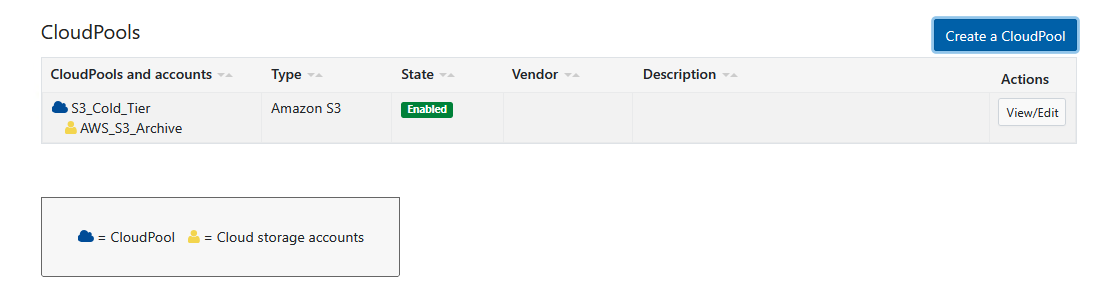
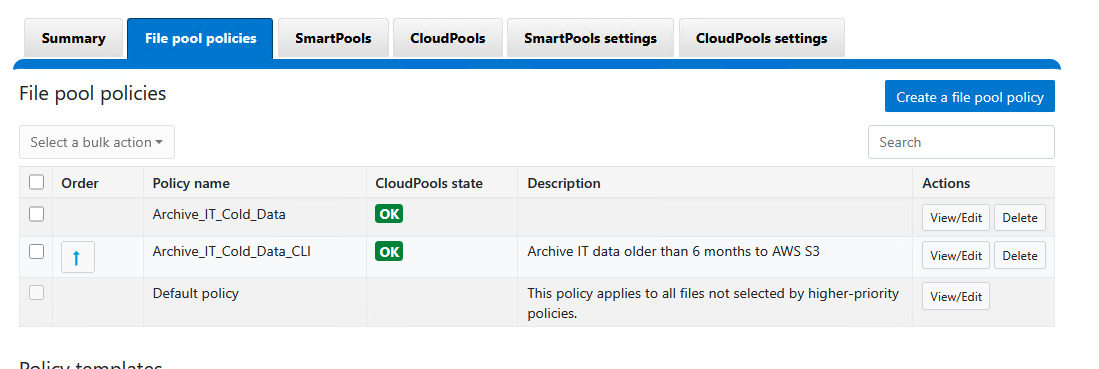
Paso 3: Configurar la Política de Archivo (FilePool Policy)
Ahora se debe instruir al motor de trabajos de Isilon sobre qué archivos deben enviarse al CloudPool. Esto se logra mediante una política de FilePool.
En este ejemplo, moveremos a S3 todos los archivos dentro del directorio de IT que no hayan sido accedidos en los últimos 6 meses.
Vía WebUI:
- Ve a File System > Storage Pools > FilePool Policies.
- Haz clic en Create a FilePool Policy.
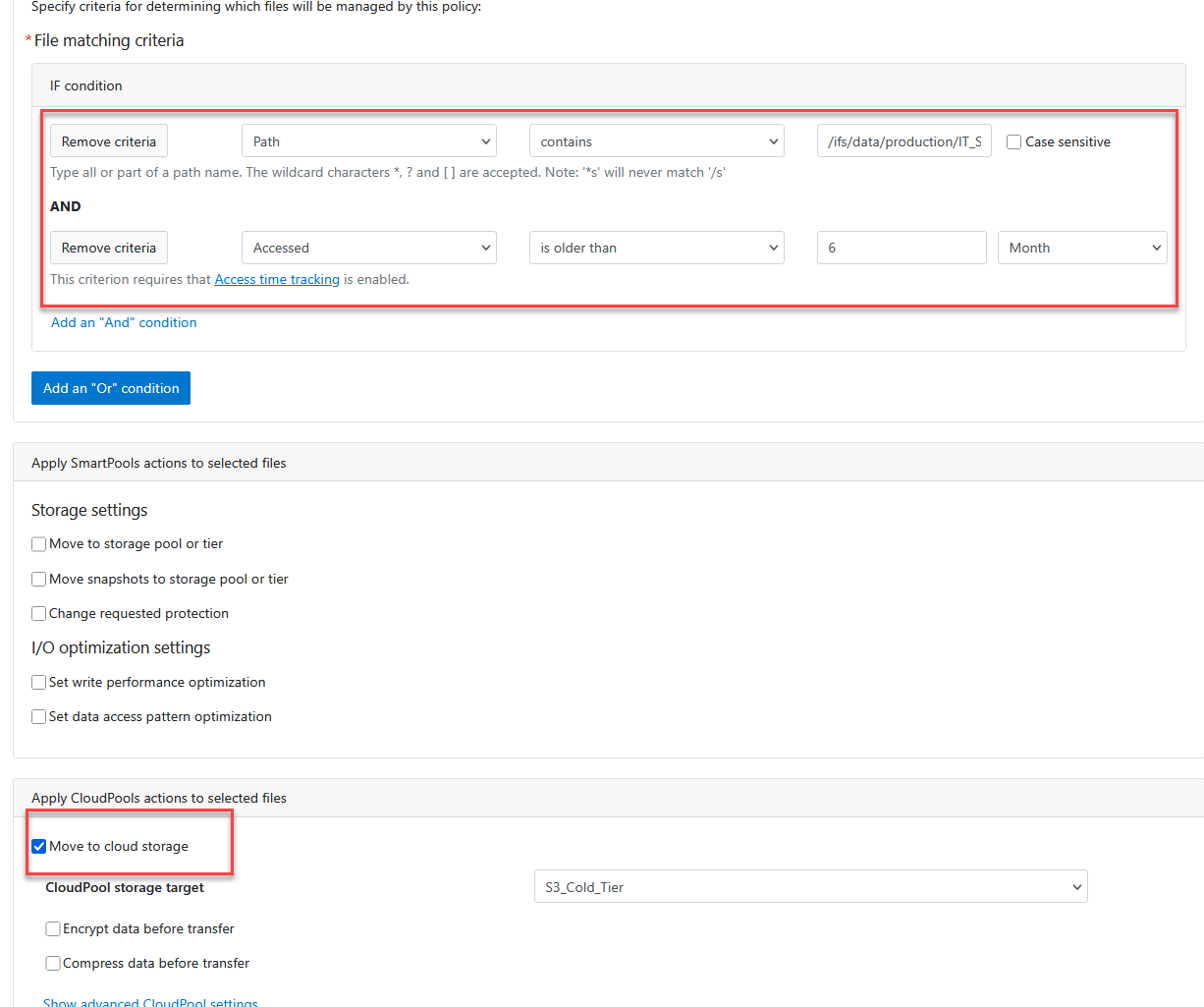
- Configura las reglas de la política:
Policy Settings
- Policy name:
Archive_IT_Cold_DataFile matching criteria
- Establece las condiciones (lógica AND):
- Selecciona
Path|contains|/ifs/data/production/IT_Share- Haz clic en Add an “And” condition.
- Selecciona
Accessed|is older than|6|Month(Nota: Deja en blanco la sección “Apply SmartPools actions to selected files”)
Apply CloudPools actions to selected files
- Marca la casilla Move to cloud storage.
- CloudPool storage target: Selecciona
S3_Cold_Tier.
- Haz clic en Create policy.
Vía CLI:
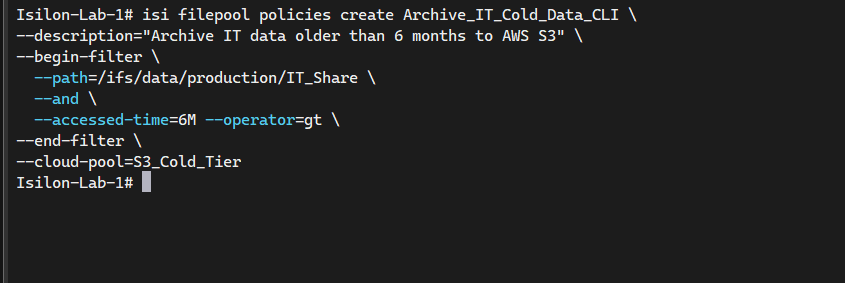
Para entornos automatizados, esta misma política lógica se puede crear desde la terminal:
# Create a FilePool policy to archive files in IT_Share older than 6 months to S3
isi filepool policies create Archive_IT_Cold_Data_CLI \
--description="Archive IT data older than 6 months to AWS S3" \
--begin-filter \
--path=/ifs/data/production/IT_Share \
--and \
--accessed-time=6M --operator=gt \
--end-filter \
--cloud-pool=S3_Cold_Tier
Paso 4: Ejecución del Trabajo (SmartPools Job)
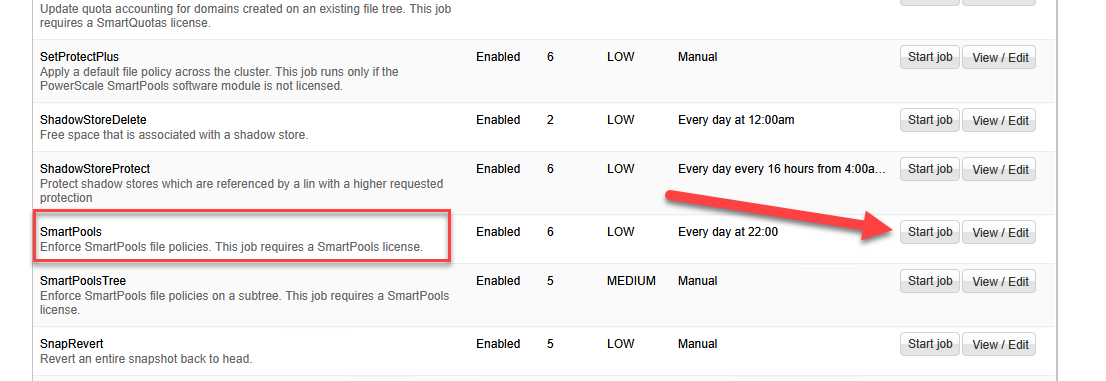
Las políticas de FilePool son evaluadas y ejecutadas por el motor de trabajos mediante el job llamado SmartPools. Por defecto, este trabajo corre de forma automatizada. Para forzar la evaluación inmediata y comenzar el movimiento de datos a AWS:
Vía WebUI:
- Ve a Cluster Management > Job Operations > Job Types.
- Localiza el trabajo SmartPools y haz clic en Start Job.
Vía CLI:
# Start the SmartPools job to evaluate FilePool policies and move data to S3
isi job jobs start SmartPools
# Check the status of the job
isi job jobs list
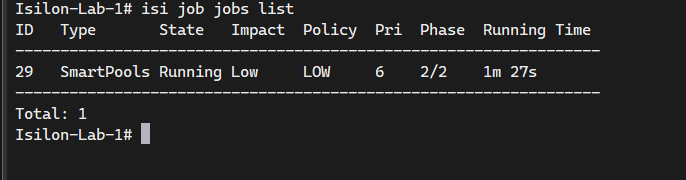
Validación de Resultados
Una vez que el trabajo de SmartPools finalice, los archivos que cumplan con el criterio en el directorio especificado serán reemplazados por SmartLinks. En la interfaz de comandos o en exploradores de archivos que soporten visualización de atributos extendidos, estos archivos mostrarán un tamaño en disco (Size on disk) cercano a 0 bytes, indicando que el bloque de datos pesado ha sido transferido exitosamente al almacenamiento externo.
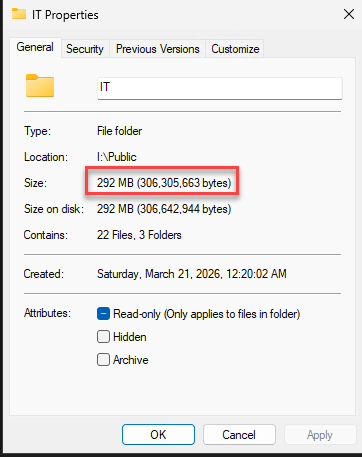
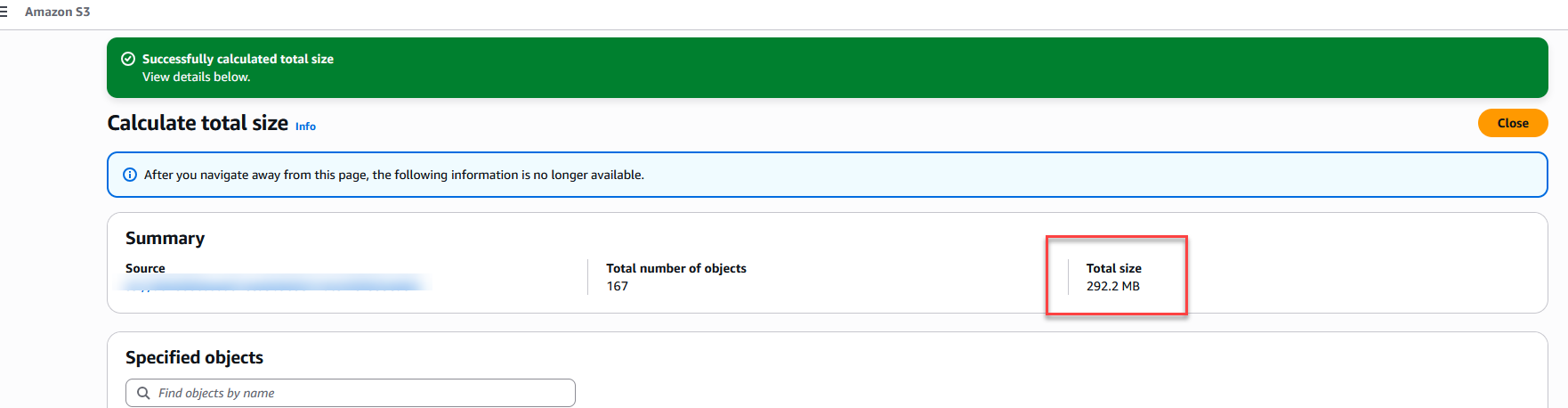
El “Gotcha” del Size on Disk
Es muy común que en las primeras versiones de OneFS o en simuladores, el explorador de Windows no refresque inmediatamente el Size on disk a un valor cercano a cero hasta que el caché del clúster se limpie o los archivos se marquen explícitamente como “Offline”.
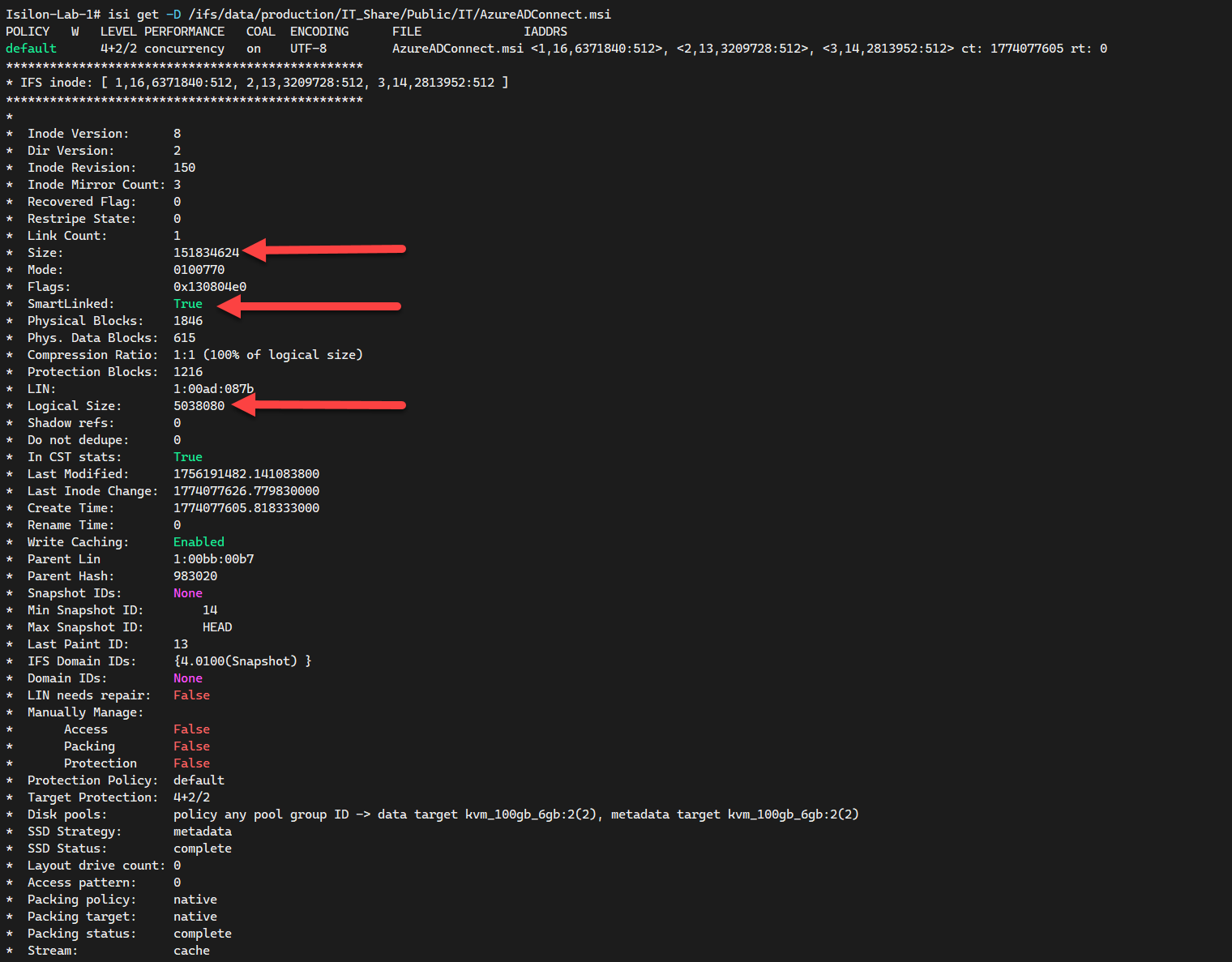
Para confirmar que la estratificación fue efectiva, no basta con ver el bucket de AWS; debemos interrogar al sistema de archivos OneFS para verificar el estado del inodo. Al ejecutar el comando isi get -D, obtendrás la “radiografía” técnica del archivo.
# Analyze the specific file inode to verify SmartLink status
isi get -D /ifs/data/production/IT_Share/Public/IT/yourfile.extention
¿Qué buscar en la salida del comando?
SmartLinked: True: Esta es la bandera definitiva. Confirma que el cuerpo del archivo (los datos pesados) ha sido movido al CloudPool (AWS S3) y lo que queda en el Isilon es solo el “stub” o puntero de referencia.Logical SizevsSize: Verás una discrepancia real. ElSizerepresenta el tamaño original del archivo, mientras que elLogical Size(o el conteo de bloques físicos locales) mostrará un valor drásticamente menor, indicando el ahorro de espacio local.BCM metadata: La presencia de metadatos de Backup Content Mode al final del reporte indica que OneFS está rastreando la ubicación del objeto en Amazon S3 para su recuperación transparente.
Análisis de Costos y el “Gotcha” de la Data Fría en S3
Cuando OneFS envía su “data fría” hacia AWS mediante CloudPools, de manera nativa sube los objetos usando la clase de almacenamiento S3 Standard por defecto. Este es un “gotcha” arquitectónico sumamente crítico: estás moviendo información porque es inactiva y no quieres gastar, pero podrías terminar pagando precios premium de nube “caliente” ($0.023 por GB) para archivarla.
¿Vale verdaderamente la pena? Veamos el impacto mensual asumiendo que el crecimiento en S3 Standard puro escale sin control:
- 1 TB: ~$23 USD / mes
- 5 TB: ~$115 USD / mes
- 10 TB: ~$230 USD / mes
S3 Intelligent-Tiering al Rescate
Para maximizar el ahorro sin romper el acceso transparente para los usuarios, la mejor práctica técnica es configurar tu bucket de AWS usando la clase S3 Intelligent-Tiering. AWS monitoreará automáticamente los miles de objetos fragmentados (“CDOs”) inyectados por Isilon; si nadie los solicita en 30 días, AWS los mueve a un nivel de costo mucho menor (Infrequent Access), y después de 90 días, al nivel de Archive Instant Access. Hagamos de nuevo los números bajo este último nivel ($0.004 por GB):
- 1 TB: ~$4 USD / mes (Ahorro del 82%)
- 5 TB: ~$20 USD / mes
- 10 TB: ~$40 USD / mes
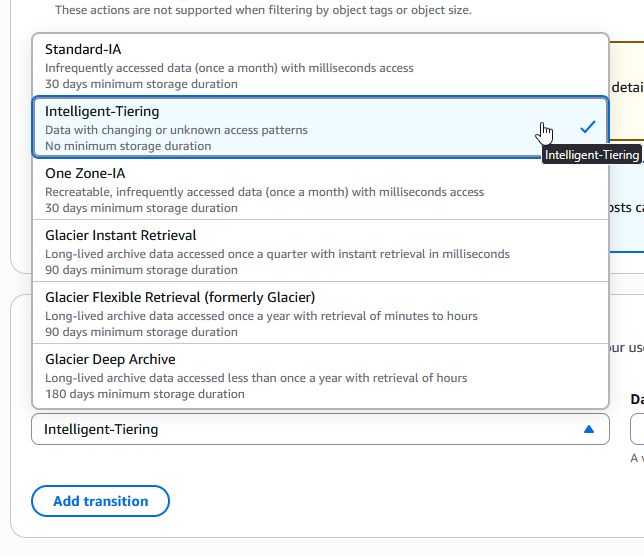
¿Romperá la conexión? ¿Habrá retrasos (delays)? El requisito más crítico y absoluto para CloudPools es la recuperación síncrona en milisegundos. Si hay grandes demoras u horas de espera, el sistema operativo del usuario arrojará automáticamente un Timeout o File Not Found. La maravilla de las capas automáticas de Intelligent-Tiering (Frequent, Infrequent y Archive Instant Access) es que todas entregan la misma latencia de milisegundos que S3 Standard. No hay tiempos de espera prolongados, conexiones rotas, ni errores de E/S. El usuario final accederá al archivo al instante, mientras la empresa ahorra hasta un 82% en su facturación cloud. (Nota: Esto aplica únicamente para las capas de tránsito automáticas; asegúrate de NO activar las capas opcionales “Archive Access” o “Deep Archive Access” dentro de Intelligent-Tiering, ya que esas sí son totalmente asíncronas de 1 a 12 horas y romperán la integración nativa con OneFS).
Pro-Tip: El peligro de las políticas de ciclo de vida de AWS (Glacier) Cuidado: No habilites reglas de ciclo de vida en S3 que muevan los datos de Isilon hacia S3 Glacier (Flexible Retrieval o Deep Archive) de forma automatizada o agresiva.
Isilon CloudPools fragmenta los archivos pesados en miles de pequeños objetos y espera recuperarlos en la escala de milisegundos en cuanto un usuario interactúa con ellos en Windows. Si AWS empuja unilateralmente estos objetos a Glacier, el tiempo de restauración asíncrono (típicamente de 1 a 12 horas) causará un Timeout a nivel clúster. Isilon no sabe decirle al usuario en tiempo real “espera 4 horas”; simplemente marcará el archivo como corrupto o enviará un “I/O Error” irremediable.
Conclusión
CloudPools es una herramienta fantástica para recuperar rápidamente la inversión en almacenamiento primario escalable (Scale-Out NAS), externalizando la data fría de un modo completamente transparente para el usuario final. Al descargar su archivo muerto hacia la nube, se prolonga dramáticamente la vida útil del clúster On-Premise y se preservan las IOPS críticas. Con una orquestación cuidadosa y reglas bien definidas en la nube, como adoptar Inteligent-Tiering, se configura una arquitectura verdaderamente híbrida, moderna, de bajo costo y alto rendimiento estructural.
End of transmission.